
Mọi người dùng container có thể từng cảm giác kiểu, thấy các container tool trên macOS hoặc Windows đôi khi không mượt như trên Linux.
Nếu chưa benchmark thì đó là cảm nhận và cũng chưa xác định được chậm thật thì chậm ở đâu?, những bottleneck nào?, nếu so với Docker thì sao?
Các bác đã biết thì container trên macOS và Windows phải chạy qua một Linux VM. Nhưng gần đây coi mấy tài liệu Podman, mình thấy nó đúng mà chưa đủ. Nói do VM nên chậm cũng giống như nói API chậm vì backend xử lý lâu. Cảm giác rất hợp thức hóa, nhưng không giải quyết được vấn đề.
Nên là biến một cảm giác mơ hồ thành dữ liệu đo đếm cụ thể là cách hay nhất, mình học hỏi và các bác xem thử nhé.
Chậm là chậm ở đâu?
Khi nói một tool container bị chậm, mình thường nghĩ ngay đến vài lệnh thao tác nhanh:
podman build .
podman pull nginx
podman load -i image.tar
podman rmi imageNhìn bên ngoài thì đều là Podman chạy chậm. Nhưng bên trong, mỗi lệnh lại đụng đến một phần khác nhau.
build có thể chậm vì build context lớn.
pull có thể chậm vì network hoặc connection handling.
load có thể chậm vì file tar lớn.
rmi có thể chậm vì cách storage xóa image layer.
Nhìn lại thấy một mindset nảy luôn trong đầu khi làm nghề là không nên tối ưu một hệ thống khi mình còn chưa biết nó chậm ở đoạn nào.
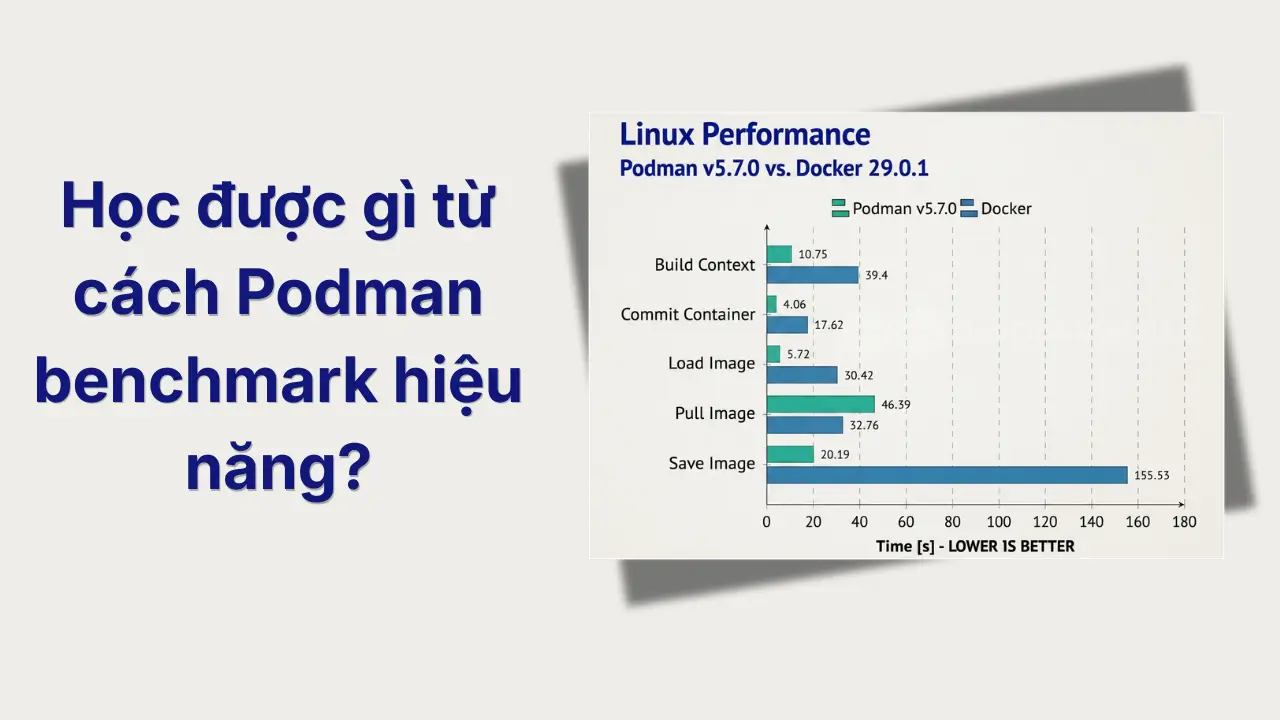
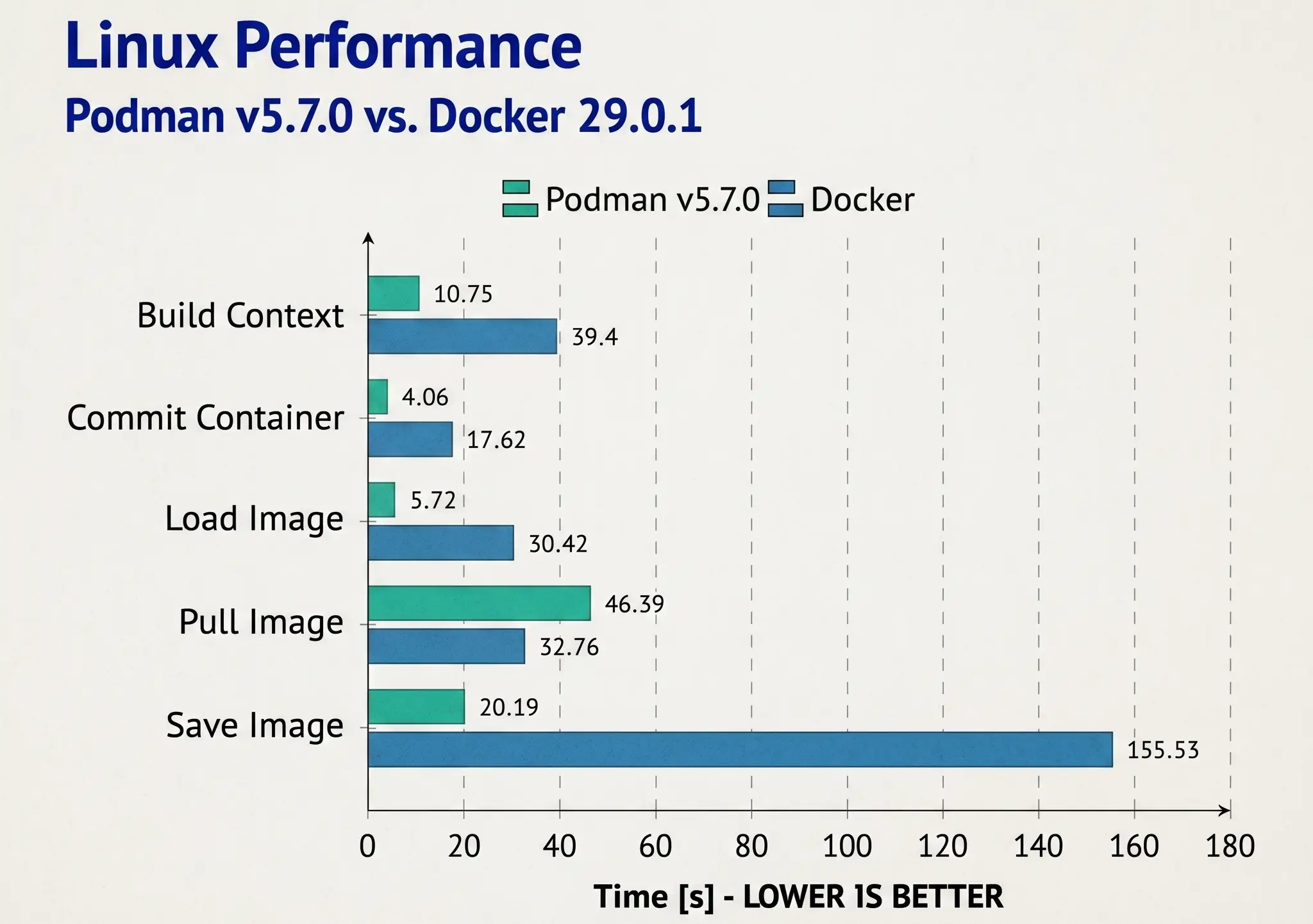
Trong những tài liệu chia sẻ của Podman, việc dùng benchmark tự động trên Linux, macOS và Windows để so sánh nhiều workload khác nhau. Điều này không chỉ đo một command đơn lẻ, mà đo nhiều tình huống gần với cách người dùng thật sử dụng container tool hằng ngày.
Mình thấy đây là phần quan trọng nhất. Benchmark tốt phải giúp mình ra quyết định: nên sửa chỗ nào trước.
Một bottleneck nhỏ: giữ lock quá lâu
Ví dụ mình thấy hay nhất là chuyện xóa image layer.
Trước đây, khi Podman xóa layer trong storage, nó có thể giữ một global lock trong lúc làm disk I/O. Lock thì cần thiết, vì storage phải tránh trạng thái dữ liệu bị sửa đồng thời lung tung. Nhưng nếu giữ lock quá lâu, hệ thống sẽ mất khả năng chạy song song.
Có thể hình dung thế này:
Process A đang xóa một image lớn và giữ lock
Process B cần thao tác với storage -> phải chờ
Process C cũng cần storage -> tiếp tục chờVấn đề không phải là có lock. Vấn đề là lock bị giữ trong lúc làm việc nặng với disk.
Cách Podman xử lý khá là thực dụng khi chuyển layer cần xóa sang thư mục tạm, nhả lock sớm, rồi mới xóa dữ liệu sau.
Giữ lock
-> chuyển layer sang thư mục tạm
-> nhả lock
-> xóa dữ liệu sauMình thích ví dụ này vì nó rất gần với các vấn đề performance ngoài đời. Không phải lúc nào bottleneck cũng là thuật toán phức tạp hay thiếu tài nguyên. Đôi khi chỉ là một đoạn code đang serialize quá nhiều việc.
Bài học rút ra là nếu hệ thống có concurrency mà vẫn chậm, hãy kiểm tra xem có phần nào đang vô tình bắt mọi thứ xếp hàng không.
Một bottleneck khác: dữ liệu đi vòng quá xa
Vấn đề thứ hai nằm ở macOS và Windows.
Vì Podman phải chạy trong Linux VM, dữ liệu từ host cần đi vào môi trường VM. Với những thao tác như:
podman build .
podman load -i big-image.tarLượng dữ liệu có thể rất lớn. Nếu build context hoặc file image tar được truyền qua REST API vào VM, chi phí sẽ tăng lên đáng kể.
Nên là cũng có thể thấy rõ không phải cái gì cũng nên đi qua API.
Nếu filesystem của host đã được mount vào VM, thì VM có thể đọc trực tiếp dữ liệu đó. Thay vì gửi cả file qua API, chỉ cần để phía VM truy cập file thông qua mount.
So sánh ngắn gọn:
Cũ: host đọc file -> gửi qua REST API -> VM nhận -> xử lý
Mới: VM đọc trực tiếp file từ filesystem đã mount -> xử lýĐây là kiểu tối ưu nghe đơn giản, nhưng rất đáng giá. Trong hệ thống nhiều lớp, chi phí di chuyển dữ liệu đôi khi còn đáng kể hơn chi phí xử lý dữ liệu.
Mình thấy bài học này áp dụng được khá rộng. Ví dụ trong backend, data pipeline hay CI/CD, nếu dữ liệu cứ bị copy qua nhiều tầng không cần thiết, hiệu năng sẽ xuống rất nhanh.
Điều đáng học không nằm ở chuyện Podman hơn Docker
Như các tài liệu Podman rất hay so sánh với Docker, cũng đúng thôi đó là một cách tham chiếu dễ hình dung vì Docker quá thông dụng, thực tế thì bài benchmark này Podman thắng nhưng ở cấp độ vài chục mili giây thì gần như không đáng kể, và mình không nghĩ nên đọc nó như một bài kiểu Tool nào thắng tool thua.
Docker vẫn có điểm mạnh và thị phần khó thay thế. Podman cũng có những phần đã cải thiện rất rõ, nhất là ở storage và các thao tác image/container. Cái gì hay thì mình học thôi, phần đáng giá hơn là quy trình:
Đo trên nhiều nền tảng
-> xác định workload chậm
-> tìm bottleneck thật
-> sửa đúng chỗ
-> benchmark lạiĐây mới là thứ mình thấy đáng học.
Trong thực tế, khi gặp hệ thống chậm, mình rất dễ bị kéo vào những phản xạ quen thuộc:
- Thêm cache.
- Tăng CPU.
- Đổi thư viện.
- Rewrite đoạn này.
Những cách đó có thể đúng, nhưng chỉ đúng khi mình đã biết bottleneck nằm ở đâu. Nếu chưa đo, rất dễ tối ưu nhầm chỗ.
Kết lại
Khi mình đi nghiên cứu về các giải pháp thì thật sự mình không nhớ quá nhiều vào từng con số. Thứ mình nhớ là cách tiếp cận.
Một vấn đề hiệu năng tốt nhất nên bắt đầu bằng câu hỏi: Nó chậm chính xác ở đâu?
Với Podman, câu trả lời nằm ở những chỗ rất cụ thể có lúc là global lock trong storage, có lúc là dữ liệu bị truyền vào VM qua đường không tối ưu.
Với các hệ thống khác cũng vậy. Câu hệ thống chậm chỉ là điểm bắt đầu. Muốn sửa thật sự, cần đo, bóc tách, tìm bottleneck, rồi mới tối ưu.












