Chào mọi người, lần đầu viết bài, hôm nay mình muốn chia sẻ lại một câu chuyện nhớ đời của mình dính khoảng 2 tuần trước, tính chia sẻ từ lúc đấy nhưng mà phải dành thời gian xem xét kỹ chút vì chia sẻ ra có giá trị cho anh em với câu từ mượt mượt tí nên cuối tuần mới ngồi viết.
Đây là một case study chắc cũng điển hình về việc code chạy ngon ở Local nhưng lên Production thì gặp sự cố, liên quan đến một kiến thức rất nền tảng của Linux mà đôi khi anh em làm Container hay bỏ quên.
Đó là câu chuyện về Zombie Processes và bí ẩn của PID 1.
Deploy chiều thứ 6 và hệ thống Payment bị treo
Vụ này vào chiều thứ 6, team có đẩy một bản hotfix cho Payment Service (viết bằng Node.js) lên Kubernetes Cluster. Pipeline CI/CD chạy rất mượt, image build xong, Helm release báo thành công. 5 phút sau, hệ thống monitoring bắt đầu báo động.
Khi mình nhìn vào Dashboard, các chỉ số rất lạ:
- Latency của service tăng vọt.
- Các Pod cũ (phiên bản trước) bị kẹt ở trạng thái Terminating mãi không chịu tắt.
- Các Pod mới đã Running nhưng traffic điều hướng vào không ổn định.
Mình soi kỹ log của Kubernetes events thì phát hiện ra một pattern cố định: thời gian để một Pod cũ tắt hẳn (shutdown) luôn kéo dài đúng 30 giây. Không nhanh hơn, cũng không chậm hơn.

Mình quay sang hỏi bạn Dev Lead: “Mọi người đã handle Graceful Shutdown trong code chưa? Tại sao Pod không thoát ngay mà cứ treo thế này?”
Bạn ấy khẳng định: “Code bên em đã xử lý sự kiện SIGTERM để đóng Database connection và flush log rồi. Ở Local em chạy thử, bấm Ctrl+C là app dừng ngay lập tức.”
Vậy vấn đề nằm ở đâu? Nếu code đúng, tại sao lên môi trường Production lại sai? Tại sao con số lại là đúng 30 giây?
Điều tra và kết quả từ ps aux
Không đoán già đoán non dựa theo kinh nghiệm nữa, mindset này học được từ việc đọc nhiều bài chia sẻ của các anh/chị/em trên này : D. Mình quyết định remote trực tiếp vào một Container đang chạy để kiểm tra Process tree bên trong.
kubectl exec -it payment-service-xyz -- /bin/sh
$ ps aux
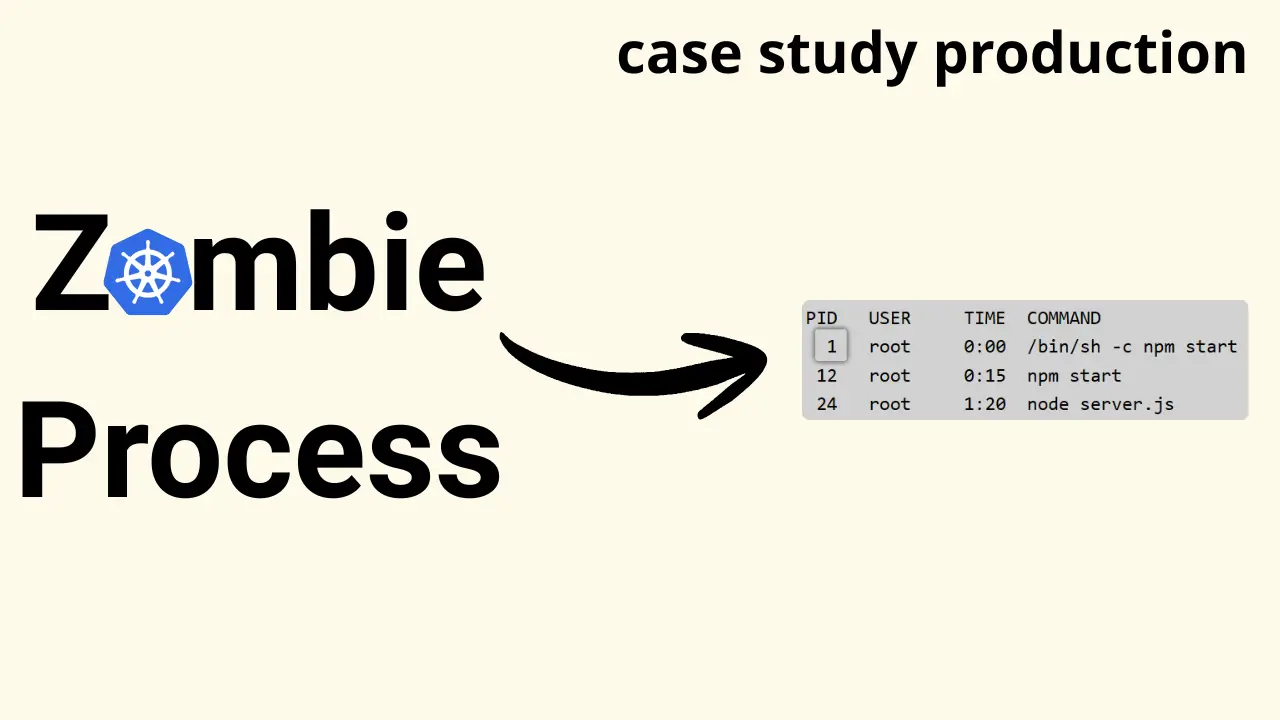
Kết quả trả về đã giải thích tất cả:
PID USER TIME COMMAND
1 root 0:00 /bin/sh -c npm start
12 root 0:15 npm start
24 root 1:20 node server.js
Anh em có thấy vấn đề không? Có 2 điểm kỹ thuật cực kỳ quan trọng ở đây:
- Process có PID 1 không phải là ứng dụng Node.js, mà là
/bin/sh. - Ứng dụng chính
node server.jsđang nằm ở PID 24, tức là nó là Child process của Child process PID 1.
Đây chính là nguyên nhân gốc rễ khiến cơ chế Graceful Shutdown mà team Dev đã code, bị vô hiệu hóa hoàn toàn.
Nguyên nhân gốc rễ là do cơ chế xử lý Signal của Linux Kernel
Để hiểu tại sao hệ thống bị lỗi, mọi người cần nhớ lại kiến thức về Operating System, cụ thể là cách Linux Kernel đối xử với PID 1.
PID 1 (Init Process) là “kẻ được chọn”: Trong hệ điều hành Linux truyền thống, PID 1 thường là systemd hoặc SysVinit. Kernel đối xử với PID 1 rất khác biệt.
- Với process thường (PID > 1): Nếu nhận tín hiệu
SIGTERMmà process không khai báo handler, Kernel sẽ thực hiện hành động mặc định là tắt process đó. - Với PID 1: Kernel mặc định BỎ QUA tín hiệu
SIGTERMnếu ứng dụng không được lập trình rõ ràng để bắt tín hiệu này. Đây là cơ chế bảo vệ của Kernel để tránh việc PID 1 bị kill nhầm gây sập hệ thống (Kernel panic).
Vấn đề khi chạy trong Kubernetes và Docker: Khi Kubernetes muốn tắt một Pod (ví dụ khi rolling update), Kubelet sẽ gửi tín hiệu SIGTERM đến đúng PID 1 bên trong Container namespace.
Quay lại case của mình:
- Kubernetes gửi
SIGTERMvào PID 1 (đang là/bin/sh). - Thằng
/bin/shlà một shell đơn giản, nó không được thiết kế để forward signal xuống cho các Child process (lànpmvànode). - Kết quả:
/bin/shnhậnSIGTERMnhưng lờ đi (do đặc quyền PID 1). Ứng dụng Node.js bên trong (nơi chứa logic Graceful Shutdown) hoàn toàn không biết gì về tín hiệu này. Nó vẫn tiếp tục nhận request và xử lý transaction như chưa có gì xảy ra.
Tại sao lại là 30 giây?
Đó chính là giá trị terminationGracePeriodSeconds mặc định trong cấu hình Pod của Kubernetes.
- Kubelet gửi
SIGTERM. - Container không phản hồi.
- Kubelet kiên nhẫn đợi hết timeout 30 giây.
- Hết giờ, Kubelet quyết định gửi
SIGKILL. - Lúc này Kernel buộc phải kill process ngay lập tức (Hard kill). Database connection bị ngắt đột ngột, các request đang xử lý dở dang bị drop, dẫn đến lỗi 5xx trả về cho Client.
Lỗi sai nằm ở Dockerfile
Lý do khiến /bin/sh chiếm lấy PID 1 nằm ở thói quen viết instruction CMD trong Dockerfile của nhiều anh em.
Cách viết sai (Shell form):
CMD npm start
Khi Docker build dòng này, nó sẽ tự động wrap command bằng shell: /bin/sh -c npm start. Điều này làm cho shell trở thành PID 1.
Cách viết đúng (Exec form):
CMD ["npm", "start"]
Hoặc tốt hơn là gọi thẳng vào runtime:
CMD ["node", "server.js"]
Lúc này, Docker sẽ chạy process node trực tiếp và nó sẽ nhận được PID 1.
Tuy nhiên, mình lưu ý là ngay cả khi node là PID 1, ứng dụng vẫn có thể không shutdown đúng cách nếu runtime của ngôn ngữ đó (như Java, Node.js, Python) không handle signal chuẩn xác như một Init system thực thụ.
Giải pháp triệt để mình sử dụng Tini
Cách xử lý chuẩn Best-practice cho môi trường Production mà mình khuyên mọi người dùng không phải là cố ép Application code làm nhiệm vụ của Init process. Thay vào đó, hãy dùng một công cụ chuyên dụng như tini.
tini là một Init process cực nhẹ, sinh ra để dành cho Container.
Cơ chế hoạt động của Tini:
tinichạy với PID 1.tinispawn ra App của anh em (App sẽ là PID 2, 3…).- Khi Kubernetes gửi
SIGTERMvàotini(PID 1).tinisẽ forward tín hiệu đó ngay lập tức xuống cho Child process (App). - Vì App lúc này không phải PID 1, nó nhận
SIGTERMvà thực hiện Graceful Shutdown bình thường. - Ngoài ra,
tinicòn giúp dọn dẹp các Zombie process (các process con bị chết mà Parent không wait) để tránh leak resource.
Cách implement trong Dockerfile:
FROM node:18-alpine
# Cài đặt tini
RUN apk add --no-cache tini
# Copy source code...
COPY . .
# Sử dụng tini làm Entrypoint
ENTRYPOINT ["/sbin/tini", "--"]
# Command chạy app
CMD ["node", "server.js"]
Bài học rút ra
Sau sự cố này, mình đã rút ra được vài kinh nghiệm chắc nhiều anh em sẽ cần khi vận hành hệ thống trên Cloud:
- Local Environment khác xa Production: Ở Local, mọi người chạy
npm starttrên terminal rồi bấm Ctrl+C, lúc đó shell của máy tính gửi signal trực tiếp vào Process group. Nhưng trong môi trường Containerized, các lớp abstract của Runtime và Namespace làm thay đổi hành vi này. Đừng bao giờ tin tưởng tuyệt đối vào việc chạy ngon ở Local. - Process Lifecycle là yếu tố sống còn: Viết code cho Microservices không chỉ là xử lý Business logic. Mọi người phải kiểm soát được cách ứng dụng khởi tạo (Startup probe) và cách nó kết thúc (Graceful shutdown).
- Tránh Hard Kill bằng mọi giá: Trong môi trường Production, Pod có thể bị evict hoặc restart bất cứ lúc nào (do Autoscaling, Spot instance reclamation). Nếu ứng dụng luôn chờ bị
SIGKILL(sau 30s) mới chết, dữ liệu sẽ có nguy cơ bị corrupt và trải nghiệm người dùng sẽ bị ảnh hưởng nghiêm trọng.
Nhìn thấy việc thêm tini và sửa lại cú pháp Dockerfile sang Exec form, team mình đã giải quyết triệt để vấn đề High Latency khi deploy và loại bỏ hoàn toàn các lỗi kết nối Database do process bị kill đột ngột. Nhưng đó là cả quá trình debug mới tìm ra nguyên nhân nên hy vọng chia sẻ này giúp ích cho mọi người trong quá trình vận hành hệ thống.
Nằm vùng học hỏi đã lâu cũng phải tính bằng năm, giờ mới dám viết chia sẻ, cảm ơn các sếp DevOps VietNam đã tạo ra sân chơi cho anh em được chia sẻ kinh nghiệm thật, học hỏi thật, và tạo ra các sự kiện giá trị.