
Khi Dùng UUID Làm Khóa Chính: Tiện Lợi Thì Có, Mà Bẫy Cũng Nhiều
Ai làm database chắc cũng quen với cái vụ dùng UUID để định danh cho mỗi row rồi. Nghe thì có vẻ hay ho, cứ mỗi cái ID là một dãy ký tự dài loằng ngoằng, đảm bảo khó có thể trùng nhau. Nhưng mà, cái món này nó có mấy cái bẫy về hiệu năng mà mình không biết là dễ dính.
Trong bài này, anh em cùng nghiên cứu hai vấn đề lớn mà UUID hay gây ra khi mình biến nó thành khóa chính trong các bảng database của mình.

Thôi không vòng vo nữa. Mình nhảy vào luôn nha anh em.
UUID là gì?
UUID là viết tắt của cái cụm Universally Unique Identifier, dịch nôm na là một cái mã định danh duy nhất trên toàn cầu. Nghe đã thấy sang chảnh rồi phải không?
Nó có nhiều kiểu lắm, nhưng mà cái loại phổ biến nhất, mà mình hay đụng tới, là UUIDv4.
Đây, anh em nhìn thử một em UUIDv4 nó trông thế này nè:
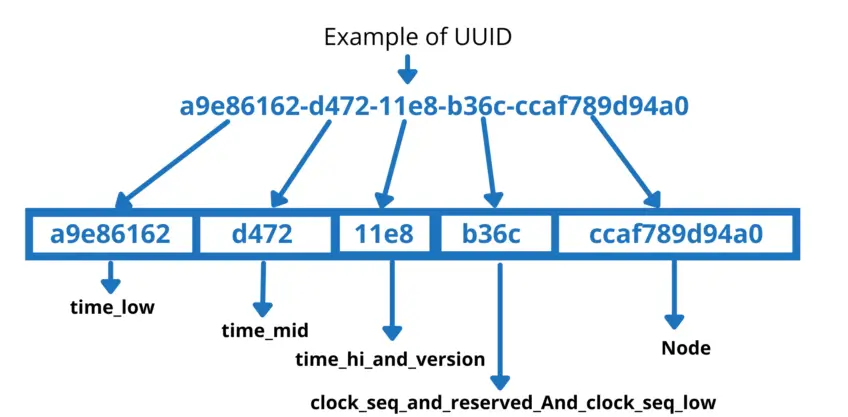
Vấn đề 1: Thêm dữ liệu chậm như rùa bò (Insert Performance)
Khi mình nhét một hàng mới vào bảng, cái index (mục lục) của khóa chính nó phải nhảy vào cập nhật ngay, để sau này mình tìm kiếm cho nhanh.
Mấy cái index này được xây dựng bằng một kiểu cây gọi là B+ Tree.
Đấy, cái vụ cân bằng lại cái cây B+ Tree này nó cực kỳ khó chịu với UUIDv4. Tại sao ư? Vì UUID nó ngẫu nhiên kinh khủng. Cứ mỗi lần thêm mới là nó lại xáo trộn hết cả lên, khiến cho cái cây khó mà giữ được sự cân bằng. Cứ thử tưởng tượng xem, khi database của anh em to lên, có hàng triệu cái node cần phải cân bằng lại, thì cái việc thêm dữ liệu nó sẽ chậm lại thấy rõ khi mình dùng UUID đó.
Vấn đề 2: Tốn không gian lưu trữ (Higher Storage)
Hãy cùng xem xét kích thước của một UUID so với một khóa số nguyên tự tăng:
So sánh đơn giản thế này: Khóa số nguyên tự tăng chỉ tốn 32 bit mỗi giá trị, trong khi UUID lại ngốn tới 128 bit lận. Tức là gấp 4 lần cho mỗi hàng đó anh em.
Chưa kể, đa số mọi người thường lưu trữ UUID dưới dạng chuỗi ký tự dễ đọc, điều đó có nghĩa là một UUID có thể tiêu tốn tới 688 bit mỗi giá trị. Con số này xấp xỉ gấp 20 lần so với khóa số nguyên.
Để anh em dễ hình dung, mình sẽ mô phỏng một database thực tế để xem UUID ảnh hưởng đến dung lượng lưu trữ như thế nào. Mình sẽ dùng các bảng được Josh Tried Coding sử dụng trong ví dụ này: Ví dụ này sử dụng database Neon Postgresql.
- Bảng 1 sẽ chứa 1 triệu hàng với UUID.
- Bảng 2 sẽ chứa 1 triệu hàng với số nguyên tự tăng.
Và đây là kết quả, mình cùng phân tích từng chỉ số một nhé:
| UUID | Integer | |
|---|---|---|
| Total table size | 146 MB | 64 MB |
| ID Field Size | 37 Bytes | 4 Bytes |
| ID Column Size | 73 MB | 21 MB |
- Tổng kích thước bảng: Khi xét cả hai bảng, bảng dùng UUID nó to hơn bảng dùng Integer khoảng 2.3 lần luôn đó anh em.
- Kích thước trường ID: Một cái trường UUID riêng lẻ nó cần dung lượng lưu trữ nhiều hơn cái trường số nguyên tương đương tới 9.3 lần đó.
- Kích thước cột ID: Khi loại trừ các thuộc tính khác trong mỗi bảng, chỉ tính riêng cột ID thôi, thì cột UUID vẫn to hơn cột số nguyên tới 3.5 lần.
Giải pháp khắc phục
Dù UUID có những ưu điểm về tính duy nhất toàn cục, mình vẫn có cách để giảm thiểu tác động tiêu cực của nó. Anh em có thể cân nhắc một số giải pháp sau:
- Dùng UUID tuần tự (sequential UUID):
- Chuyển từ UUIDv4 hoàn toàn ngẫu nhiên sang UUIDv1, UUIDv6 hoặc các thư viện sinh UUID tuần tự khác (như pgcrypto với gen_random_uuid() kết hợp uuid_generate_v1mc()).
- UUID tuần tự sẽ tập trung vị trí chèn cuối cùng của index, giảm chi phí tái cân bằng B+ Tree.
- Lưu trữ dưới dạng nhị phân (binary) thay vì chuỗi ký tự:
- Thay vì dùng CHAR(36) hay VARCHAR, sử dụng BYTEA (PostgreSQL) hoặc BINARY(16) (MySQL) để lưu UUID dưới dạng 16 bytes thuần.
- Cách này giúp giảm gần một nửa dung lượng so với chuỗi đọc được.
- Kết hợp integer surrogate key & UUID:
- Duy trì một cột SERIAL hoặc BIGSERIAL (PostgreSQL) làm khóa chính để tận dụng hiệu năng của integer auto-increment.
- Lưu UUID vào một cột phụ với UNIQUE constraint để đảm bảo tính duy nhất toàn cục.
- Khi cần chia sẻ hoặc tổng hợp dữ liệu phân tán, vẫn có UUID để đồng bộ.
- Sử dụng ULID / CUID:
- Các định dạng như ULID hay CUID vừa giữ tính duy nhất, vừa dễ sắp xếp theo thời gian.
- ULID chỉ tốn 128 bit như UUID, nhưng tự nhiên mang tính tăng tiến theo thời gian, giúp cải thiện performance của index.
- Partitioning & Sharding:
- Với bảng quá lớn, chia nhỏ bảng theo thời gian hoặc key để giảm kích thước từng partition.
- Kết hợp partitioning với UUID tuần tự để đảm bảo dữ liệu luôn append ở partition mới nhất.
- Tuning Fillfactor & Maintenance:
- Điều chỉnh FILLFACTOR của index để cho phép chèn thêm mà không tái cân bằng quá sớm.
- Thực hiện định kỳ REINDEX hoặc VACUUM (PostgreSQL) để làm gọn lại index.
- Batch Insert & Bulk Load:
- Với khối lượng dữ liệu lớn, gộp nhiều insert thành lô (batch) hoặc sử dụng COPY (PostgreSQL) để tối ưu I/O.
Chốt lại vấn đề
UUID thì tuyệt vời ở chỗ nó rất hữu ích trong việc trùng lặp ID trong database. Tuy nhiên, mấy cái vấn đề mà tôi vừa kể trên nó chỉ lộ mặt ra rõ ràng khi database của mình đạt đến quy mô cực lớn thôi. Cho nên, dùng UUID thì cũng không thấy hiệu năng bị chậm đi đáng kể đâu.
Áp dụng các giải pháp trên, anh em có thể vừa tận dụng được tính duy nhất toàn cục của UUID, vừa giảm thiểu tác động đến hiệu năng và chi phí lưu trữ. Chúc anh em build database thật “sướng”, đỡ phải đau đầu với B+ Tree và chỉ số storage nha.




















