
Uber hoàn tất chuyển đổi stateless workloads sang Kubernetes: Hành trình hiện đại hóa hạ tầng ở quy mô toàn cầu
Trong năm 2024, Uber đã chính thức hoàn thành quá trình chuyển đổi toàn bộ nền tảng điều phối container stateless từ Apache Mesos sang Kubernetes. Đây là phần đầu tiên trong chuỗi bài viết chia sẻ các tình huống triển khai thực tế khi Uber từng bước đưa mọi loại workload bao gồm batch, stateless và lưu trữ lên Kubernetes. Mục tiêu lớn nhất là tận dụng công nghệ tiêu chuẩn ngành, hệ sinh thái phong phú và độ ổn định vượt trội. Bài viết này tập trung vào quá trình di chuyển toàn bộ dịch vụ stateless dùng chung, trình bày những lý do thúc đẩy thay đổi, các thách thức kỹ thuật đã gặp, giải pháp đã áp dụng và những điều chỉnh cần thiết để đảm bảo quá trình chuyển đổi diễn ra suôn sẻ. Những phần tiếp theo sẽ nói về việc Uber chuyển các job batch từ Peloton sang Kubernetes và các mô hình kiến trúc tương lai.
Nhóm Container Platform phụ trách quản lý hơn 50 cụm tính toán trải rộng trên nhiều vùng và nền tảng, từ trung tâm dữ liệu riêng đến các nhà cung cấp dịch vụ đám mây như Oracle Cloud và Google Cloud. Mỗi cụm bao gồm từ năm nghìn đến bảy nghìn năm trăm máy chủ, tương ứng với khoảng hai trăm năm mươi nghìn lõi xử lý và năm mươi nghìn pod. Hệ thống này vận hành hơn bốn nghìn dịch vụ sử dụng khoảng ba triệu lõi, triển khai một trăm nghìn lần mỗi ngày và khởi tạo một triệu rưỡi pod, với tốc độ trung bình khoảng một trăm ba mươi pod mỗi giây trên một cụm duy nhất. Toàn bộ hoạt động được điều phối bởi lớp federation nội bộ tên là Up, công cụ trung tâm giúp các kỹ sư phần mềm của Uber quản lý vòng đời dịch vụ.
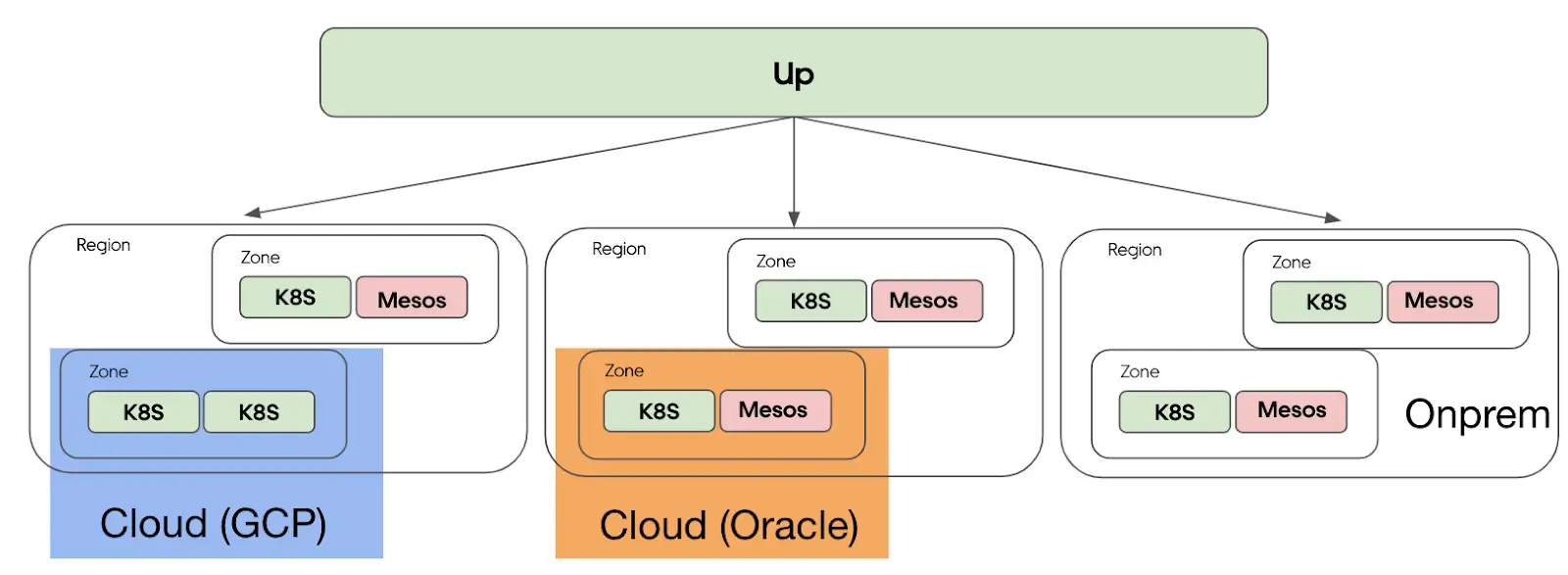
Trong khi nền tảng Mesos từng hoạt động ổn định trong suốt ba năm, việc ngừng phát triển nội bộ từ năm 2021 khiến Uber buộc phải tìm kiếm giải pháp thay thế. Dự án không còn nhận được bản vá hay cập nhật mới, tạo ra khoảng trống lớn về bảo mật và tính năng. Trong khi đó, Kubernetes trở thành tiêu chuẩn phổ biến nhất trong lĩnh vực điều phối container, được hỗ trợ mặc định bởi tất cả các nhà cung cấp đám mây lớn và liên tục được cải thiện nhờ cộng đồng mã nguồn mở sôi động. Tính tương thích lâu dài và khả năng mở rộng khiến Kubernetes trở thành lựa chọn tối ưu giúp hạ tầng của Uber có thể thích ứng với tương lai công nghệ.
Từ kinh nghiệm vận hành các nền tảng mã nguồn mở trước đó, Uber xác lập một số nguyên tắc để dẫn dắt quá trình chuyển đổi. Các phiên bản Kubernetes được lựa chọn sẽ luôn đồng bộ với các phiên bản mà nhà cung cấp đám mây đang hỗ trợ. Việc nâng cấp được đảm bảo bằng hệ thống kiểm thử tích hợp và hiệu năng toàn diện nhằm giảm thiểu sự cố. Đặc biệt, toàn bộ quá trình di chuyển được thực hiện tự động và hoàn toàn minh bạch đối với nhà phát triển, không làm thay đổi quy trình triển khai hoặc yêu cầu bất kỳ thao tác thủ công nào từ phía họ.
Quy mô vận hành của Uber tạo ra hàng loạt thách thức chưa từng gặp. Khác với thông lệ phổ biến trong ngành là chia thành nhiều cụm nhỏ, Uber lại chọn cách xây dựng các cụm cực lớn với số lượng máy chủ lên tới bảy nghìn năm trăm mỗi cụm. Quy mô như vậy giúp tối ưu tài nguyên và giảm chi phí vận hành nhưng cũng dẫn đến tải nặng lên API server, độ trễ khi lập lịch pod và hiện tượng phân mảnh nội tại. Uber xây dựng bộ công cụ đánh giá hiệu năng riêng, giúp đạt được ngưỡng tối đa với hai trăm nghìn pod hoạt động và một trăm năm mươi pod được lập lịch mỗi giây. Để đạt được điều này, nhiều lớp cấu hình đã được điều chỉnh như giới hạn truy cập API, tăng song song hóa, chuyển đổi mã hóa từ JSON sang Proto và tùy biến thuật toán phân bố pod để cải thiện tốc độ xử lý.
Một thách thức lớn khác đến từ việc phải tái tích hợp toàn bộ hệ sinh thái nội bộ. Do sự khác biệt về kiến trúc giữa Mesos và Kubernetes, nhóm kỹ sư phải xây dựng lại hoàn toàn các hệ thống liên quan như triển khai liên tục, bảo mật, khám phá dịch vụ, quan sát hệ thống và quản lý vòng đời máy chủ.
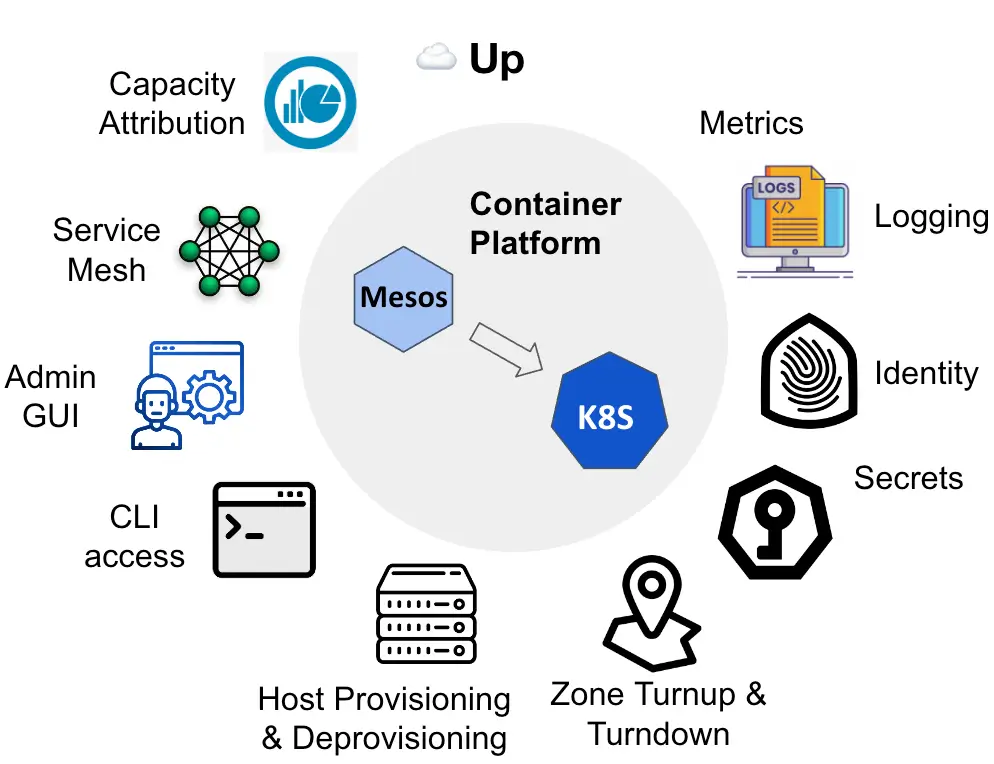
Với quy mô lên đến ba triệu lõi xử lý, việc điều chuyển thủ công là điều không thể. Uber đã tận dụng công cụ điều phối Up để tự động hóa quá trình này. Tại mỗi khu vực, một cụm Kubernetes mới được bổ sung song song với cụm Mesos hiện có. Hệ thống tự động cân bằng tải dịch vụ từ cụm sử dụng cao sang cụm sử dụng thấp mà không yêu cầu bất kỳ thay đổi nào từ phía kỹ sư dịch vụ. Trong nhiều trường hợp, chủ dịch vụ thậm chí không hề nhận ra quá trình di chuyển đang diễn ra.
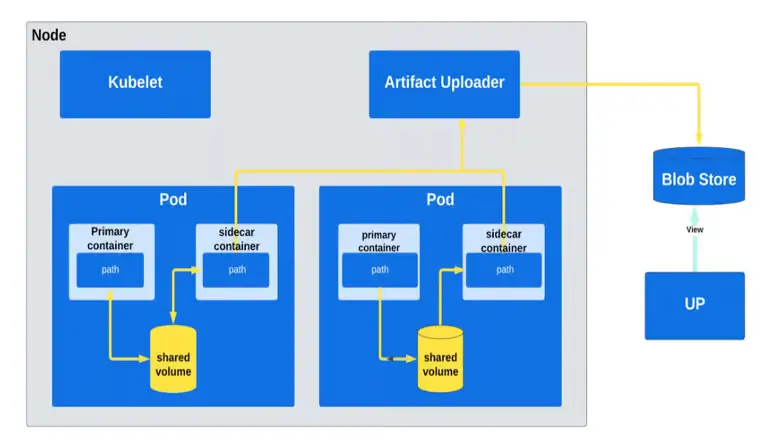
Để đảm bảo trải nghiệm lập trình viên không bị ảnh hưởng, Uber cần duy trì tính năng tương đương giữa hai nền tảng. Trên Mesos, các artifact như core dump hay log có thể truy cập kể cả khi container đã kết thúc. Trên Kubernetes, local volume sẽ bị xóa khi pod kết thúc. Để khắc phục, Uber triển khai thêm một container phụ đi kèm và daemon tải dữ liệu. Khi container chính kết thúc, daemon này sẽ nén dữ liệu và tải lên kho lưu trữ blob để phục vụ mục đích phân tích lỗi.
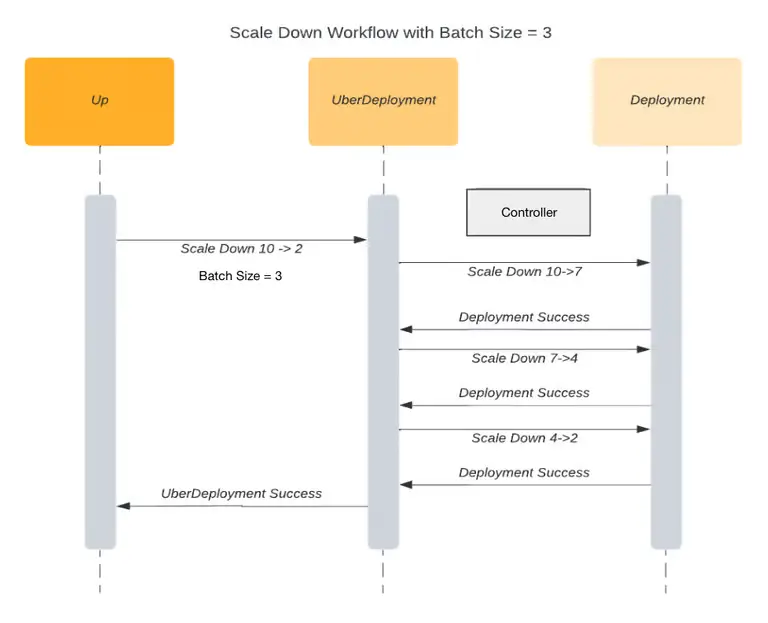
Một số dịch vụ tại Uber rất nhạy cảm với việc mở rộng nhanh chóng. Việc scale đột ngột có thể gây mất cân bằng, gây mất worker hoặc gây trễ trong các hệ thống phân mảnh. Kubernetes không có cấu hình riêng cho tốc độ scale nên Uber phải phát triển một controller tùy biến, chia nhỏ quá trình scale thành từng bước và chỉ thực hiện bước tiếp theo khi bước trước đã thành công.
Để giảm thời gian triển khai, đặc biệt với các container có dung lượng lớn, Uber áp dụng cơ chế cập nhật tại chỗ bằng cách sử dụng CloneSet. Đồng thời, một daemon được triển khai để tải sẵn ảnh container, giúp giảm thời gian khởi động ban đầu khi cập nhật dịch vụ.
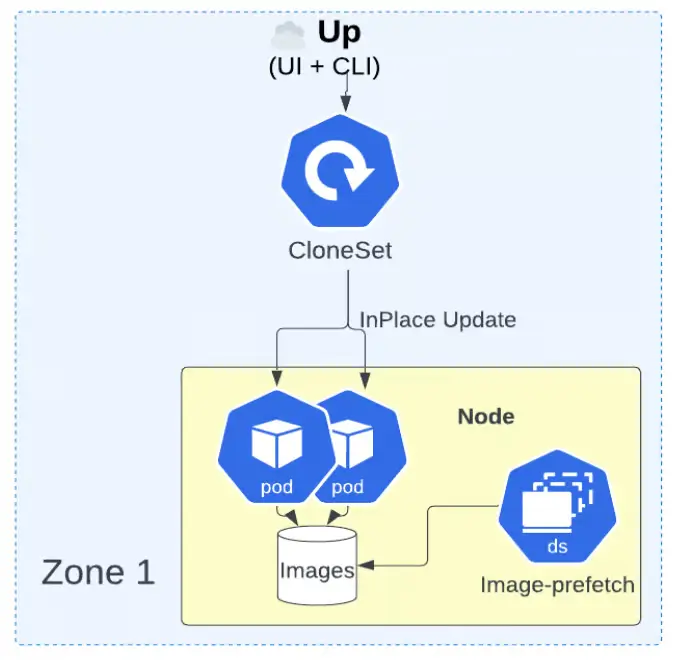
Với quy mô cụm rất lớn, giao diện người dùng mặc định của Kubernetes trở nên chậm và không đáp ứng. Uber phải tối ưu hóa giao diện bằng cách thêm nhiều lớp lưu đệm và xử lý lại logic hiển thị để đảm bảo khả năng phản hồi tốt dù hệ thống có hàng trăm nghìn thực thể đang hoạt động.
Trong quá trình di chuyển, Uber phát hiện nhiều điểm bất ngờ từ hành vi hệ thống. Các công cụ giám sát hiện có không cung cấp được cái nhìn toàn diện về sức khỏe cụm, đặc biệt là hiện tượng phân mảnh tài nguyên, ảnh hưởng giữa các pod và tác động từ việc khởi tạo lại thường xuyên. Một công cụ quan sát mới đã được xây dựng để theo dõi sâu hơn các thông số vận hành thực tế. Quá trình đồng bộ dữ liệu trong Kubernetes theo mặc định xảy ra mỗi tám đến mười giờ một lần, điều này gây ra độ trễ không chấp nhận được khi leadership của controller thay đổi. Uber khắc phục bằng cách chủ động kích hoạt đồng bộ cứ mỗi mười lăm phút. Với vấn đề rollback, tín hiệu lỗi triển khai dựa trên thời gian hết hạn là quá chậm. Thay vào đó, Uber áp dụng phương pháp dựa trên số lần khởi động lại container. Nếu trên mười phần trăm pod bị restart năm lần trở lên, hệ thống sẽ tự động kích hoạt rollback.
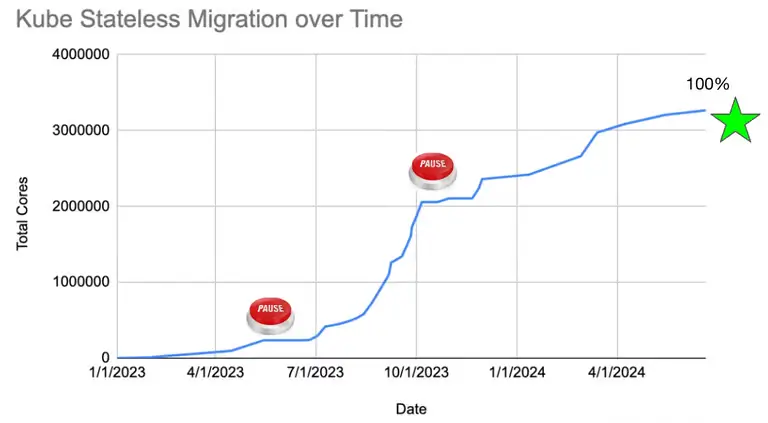
Tính đến tháng bảy năm 2024, toàn bộ dịch vụ stateless dùng chung đã được chuyển sang vận hành trên Kubernetes. Trong quá trình kéo dài gần một năm rưỡi, có những giai đoạn Uber chủ động tạm dừng triển khai để giải quyết triệt để các vấn đề về độ ổn định và hiệu năng. Các lỗi biên trong controller, các tình huống giới hạn về tải API hoặc xung đột về dữ liệu đều được xử lý triệt để trước khi tiếp tục. Nhờ đó, tốc độ triển khai tăng nhanh về cuối, có thời điểm đạt tới ba trăm nghìn lõi được chuyển trong vòng một tuần duy nhất.




















