
Tháng trước mình mới áp dụng setup hạ tầng MySQL High Availability vào Production, trước là chạy trên Kubernetes có dự án này mới setup thuần trên linux, phải chạy ổn ổn mới dám viết bài chia sẻ. Bản thân mình background làm Dev qua DevOps sau thời gian research đủ các nguồn rồi áp dụng mình có viết lại thành document để cho anh em nào cần thiết có thêm nguồn tham khảo nhé.

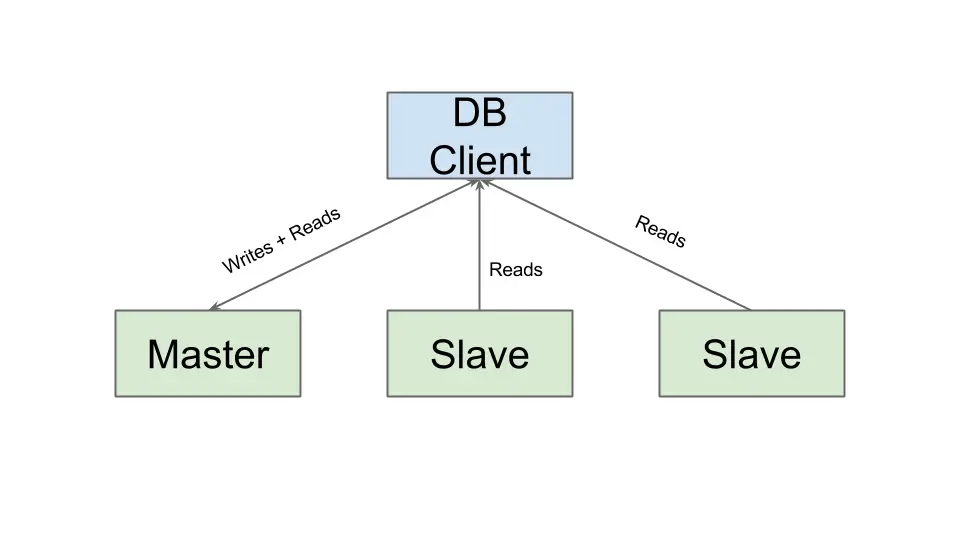
Trong lĩnh vực vận hành hạ tầng, Database là tài sản rất quan trọng anh em đều biết rồi, và sự cố trên Master Node luôn là kịch bản rủi ro rất cao. Kiến trúc Master-Slave Replication là giải pháp nền tảng để hạ tầng database từ một Single Point of Failure (SPOF) thành một thành phần có High Availability (HA).
Bài này mình sẽ tập trung vào các cấu hình và công cụ đã được kiểm chứng trong môi trường high-load, giúp anh em triển khai một kiến trúc sustainable, đáp ứng các yêu cầu về Durability, Availability, và Performance nhé.
Tại sao cần triển khai master-slave replication?
Master-Slave Replication không chỉ là một cơ chế sao lưu đơn thuần, mà là giải pháp nền tảng giải quyết 4 thách thức lớn nhất trong vận hành hệ thống:
- Đảm bảo High Availability: Khi Master gặp sự cố, các Slave có thể nhanh chóng được thay thế lên Master, giảm thiểu tối đa RTO (Recovery Time Objective), đảm bảo dịch vụ có thể hoạt động trở lại trong thời gian ngắn nhất.
- Phân tách việc đọc-ghi: Phân tải các truy vấn đọc sang các Slave, Điều này giúp Master tập trung xử lý thao tác ghi. giảm đáng kể áp lực I/O và tối ưu hiệu suất truy vấn.
- Sao lưu dữ liệu tức thời: Slave hoạt động như một bản sao thời gian thực, có thể dùng để thực hiện các công việc backup snapshot mà không ảnh hưởng đến hiệu năng của Master đang chạy trực tiếp.
- Mở rộng linh hoạt: Dễ dàng mở rộng khả năng phục vụ truy vấn đọc bằng cách bổ sung thêm Slave mà không làm gián đoạn hệ thống hiện tại.
Nói tóm lại, Master-Slave là cơ sở để hệ thống đáp ứng các yêu cầu khắt khe về dữ liệu: RPO (gần như không mất dữ liệu) và RTO (phục hồi nhanh chóng).
Phân tích cơ chế Replication
Phần lớn anh em hiểu Master-Slave chỉ đơn giản là “Master ghi, Slave đọc.” Thực tế, quá trình này là sự phối hợp chính xác của 3 thread quan trọng:
- Master’s Binlog Dump Thread: Luồng này chịu trách nhiệm đọc các sự kiện thay đổi từ binlog của Master và gửi chúng đến Slave.
- Slave’s I/O Thread: Nhận dữ liệu Binlog từ Master và ghi vào relay log trên Slave. Quá trình truyền Binlog này mặc định là bất đồng bộ.
- Slave’s SQL Thread: Đọc relay log và thực thi các câu lệnh SQL để đồng bộ dữ liệu.
Lựa chọn định dạng Binlog
Việc chọn đúng định dạng Binlog quyết định trực tiếp đến hiệu năng và tính nhất quán dữ liệu
| Format | Ưu điểm | Nhược điểm | Recommend |
|---|---|---|---|
| Statement | Kích thước log nhỏ, truyền tải nhanh. | Rủi ro mất nhất quán với các hàm không xác định (như NOW()). |
Hạn chế sử dụng. |
| Row | Đảm bảo nhất quán 100%. | Log rất lớn, tốn I/O và Network, đặc biệt khi cập nhật các bảng lớn. | Chỉ nên dùng cho hệ thống tài chính hoặc nghiệp vụ cực kỳ lớn. |
| Mixed | Cân bằng giữa hiệu năng và nhất quán. MySQL tự động chọn format tối ưu. | Đôi khi khó debug hơn một chút. | Recommend cho phần lớn các hệ thống nghiệp vụ thông thường. |
Lời khuyên của tôi: Mixed Format là lựa chọn thực dụng và hiệu quả nhất cho các ứng dụng. Anh em không nên đánh đổi hiệu năng I/O lớn chỉ để giải quyết những vấn đề nhất quán có thể tránh được bằng cách cấu hình.
GTID: Chuẩn mới cho Replication hiện đại
Cơ chế Replication truyền thống (dựa trên file/position) khiến việc quản lý và xử lý failover cực kỳ phức tạp. GTID (Global Transaction Identifier) đã trở thành tiêu chuẩn bắt buộc trong kiến trúc HA hiện đại.
GTID giải quyết vấn đề cốt lõi:
- Mỗi transaction được cấp một ID duy nhất trên toàn bộ cluster.
- Trong quá trình failover, các Slave không cần phải xác định vị trí file log (log file và position) mà chỉ cần báo cho Master mới biết transaction ID cuối cùng chúng đã thực thi.
- Đảm bảo tính nhất quán và chống trùng lặp transaction, đơn giản hóa việc quản lý khi có thay đổi topology.
Triển khai kiến Trúc Master-Slave trong môi trường Production
Setup môi trường
Phần này thì tùy cấu hình thực tế của mọi người sử dụng ra sao nhé, còn không có con số nào là hoàn hảo cho tất cả bài viết, đây là cấu hình tham khảo của mình:
- CPU: Master 6 cores. Slave 70% cấu hình Master.
- Memory: Master 24GB+, Slave không dưới 12GB.
- Disk: SSD là bắt buộc.
- OS: Ubuntu 22.04 LTS
- Phiên bản: MYSQL 8.0.3
- Công cụ Giám sát: Prometheus và Grafana
Cấu hình Master
Master cần ưu tiên sustainability và ghi log đầy đủ, chính xác.
[mysqld]
server-id = 1
port = 3306
# ... (các thông số basedir, datadir, socket)
# Cấu hình Binlog & Độ an toàn dữ liệu
log-bin = /data/mysql/binlog/mysql-bin
binlog_format = mixed
binlog_row_image = minimal # Tối ưu kích thước Log
binlog_expire_logs_seconds = 604800 # Giữ log 7 ngày
sync_binlog = 1 # Đồng bộ binlog trên mỗi commit để đảm bảo RPO=0
# Cấu hình GTID
gtid_mode = ON
enforce_gtid_consistency = ON
binlog_gtid_simple_recovery = 1
# Tối ưu Replication
binlog_transaction_dependency_tracking = WRITESET # Giúp Slave xác định các transaction độc lập
# Tối ưu InnoDB
innodb_buffer_pool_size = 20G # 60-70% Physical RAM
innodb_flush_log_at_trx_commit = 1 # bắt buộc: Đảm bảo an toàn transaction
innodb_io_capacity = 10000Cấu hình Slave
Slave cần được tối ưu hóa cho các thao tác đọc và xử lý Relay Log.
[mysqld]
server-id = 2 # bắt buộc phải là duy nhất
port = 3306
# Cấu hình Replication
relay_log_recovery = ON
read_only = ON # Slave chỉ cho phép đọc
super_read_only = ON
# Cấu hình GTID
gtid_mode = ON
enforce_gtid_consistency = ON
# Cấu hình Parallel Replication
slave_parallel_type = LOGICAL_CLOCK
slave_parallel_workers = 6 # Điều chỉnh theo số Core CPU
slave_preserve_commit_order = ON # Đảm bảo thứ tự commit
# Tối ưu InnoDB
innodb_flush_log_at_trx_commit = 2 # Có thể là 2 để tăng hiệu năng đọc
innodb_buffer_pool_size = 12GCác bước thực hiện
Bước 1: Khởi tạo User Replication
Chạy trên Master:
CREATE USER 'replicator'@'%' IDENTIFIED WITH mysql_native_password BY 'Repl@Strong';
GRANT REPLICATION SLAVE ON *.* TO 'replicator'@'%';
FLUSH PRIVILEGES;Bước 2: Khởi tạo Snapshot Dữ liệu (Dùng XtraBackup)
Sử dụng Percona XtraBackup để sao lưu hot backup trong Production.
# Thực thi backup
xtrabackup --defaults-file=/etc/my.cnf --user=root --password='YourRootPassword' \
--backup --target-dir=/backup/full --parallel=4 --compress
xtrabackup --prepare --target-dir=/backup/full
cat /backup/full/xtrabackup_binlog_infoBước 3: Restore dữ liệu trên Slave
systemctl stop mysqld
rm -rf /data/mysql/data/*
xtrabackup --copy-back --target-dir=/backup/full --datadir=/data/mysql/data
chown -R mysql:mysql /data/mysql/data
systemctl start mysqldBước 4: Cấu hình Master-Slave Replication (Sử dụng GTID)
-- Thực thi trên Slave
CHANGE MASTER TO
MASTER_HOST='10.10.254.100', -- IP của Master
MASTER_USER='replicator',
MASTER_PASSWORD='Repl@Strong',
MASTER_PORT=3306,
MASTER_AUTO_POSITION=1; -- Dùng GTID auto-positioning (bắt buộc)
START SLAVE;
SHOW SLAVE STATUS\GThiết kế kiến trúc HA và failover tự động
Triển khai MHA
MHA (Master High Availability) là giải pháp mình dùng nhiều nhất. Nó có thể chuyển đổi Master tự động failover với RTO < 30 giây mà gần như không mất dữ liệu. MHA bao gồm: MHA Manager (Node giám sát) và MHA Node (trên mỗi server MySQL).
Cài đặt MHA Manager Node
# Cài dặt MHA Manager
sudo apt update
sudo apt install -y make build-essential wget perl libdbd-mysql-perl \
libconfig-tiny-perl liblog-dispatch-perl libparallel-forkmanager-perl
# Tải MHA
wget https://github.com/yoshinorim/mha4mysql-manager/releases/download/v0.58/mha4mysql-manager-0.58.tar.gz
tar -xzf mha4mysql-manager-0.58.tar.gz
cd mha4mysql-manager-0.58
perl Makefile.PL
make && sudo make installCấu hình file MHA Manager (/etc/mha/app1.cnf):
[server default]
user=mha
password=MHA@Pass
ssh_user=root
repl_user=replicator
repl_password=Repl@Strong
manager_workdir=/var/log/mha/app1
remote_workdir=/tmp
master_ip_failover_script=/usr/local/bin/master_ip_failover
[server1]
hostname=10.10.254.100 # Master
candidate_master=1
[server2]
hostname=10.10.254.101 # Slave1
candidate_master=1ProxySQL cho phân tách Read-Write (Query Routing)
ProxySQL là một lớp Proxy tuyệt vời giúp tách Đọc/Ghi một cách tự động, ứng dụng không cần biết đâu là Master, đâu là Slave.
Cài đặt ProxySQL
wget -qO - https://repo.proxysql.com/ProxySQL/proxysql-2.5.x/repo_pub_key | gpg --dearmor | sudo tee /etc/apt/trusted.gpg.d/proxysql.gpg > /dev/null
cat <<EOF | sudo tee /etc/apt/sources.list.d/proxysql.list
deb [arch=amd64] https://repo.proxysql.com/ProxySQL/proxysql-2.5.x/debian/ jammy main
EOF
sudo apt update
sudo apt install -y proxysql
sudo systemctl start proxysql
sudo systemctl enable proxysqlCác bước cấu hình cơ bản trên ProxySQL:
-- Kết nối vào giao diện quản lý ProxySQL (Port 6032)
mysql -u admin -padmin -h 127.0.0.1 -P6032
-- 1. Thêm MySQL servers (Hostgroup 10: GHI; Hostgroup 20: ĐỌC)
INSERT INTO mysql_servers(hostgroup_id,hostname,port,weight) VALUES
(10,'10.10.254.100',3306,1000), -- Master
(20,'10.10.254.101',3306,900), -- Slave 1
(20,'10.10.254.102',3306,900); -- Slave 2
-- 2. Cấu hình Rules Phân biệt Read-Write
INSERT INTO mysql_query_rules(rule_id,match_pattern,destination_hostgroup,apply) VALUES
(1,'^SELECT.*FOR UPDATE$',10,1),
(2,'^SELECT',20,1),
(3,'^SHOW',20,1),
(4,'.*',10,1);
-- 3. Load cấu hình vào Runtime
LOAD MYSQL SERVERS TO RUNTIME;
LOAD MYSQL QUERY RULES TO RUNTIME;Test failover tự động
# 1. Kiểm tra cấu hình MHA
masterha_check_repl --conf=/etc/mha/app1.cnf
# 2. Khởi động MHA Manager
nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf > /var/log/mha/app1/manager.log 2>&1 &
# 3. Giả lập Master sập
systemctl stop mysqld # Thực thi trên Master
tail -f /var/log/mha/app1/manager.logTối ưu hiệu năng: Giảm thiểu Replication Lag trên MySQL
Replication Lag là vấn đề thường gặp xảy ra khi luồng SQL Thread trên Slave không theo kịp tốc độ ghi Binlog trên Master. Với MySQL 8.0.3 trở lên, chúng ta tập trung tối ưu vào Parallel Replication dựa trên cơ chế Logical Clock.
Kích hoạt và tối ưu Parallel Replication
Cơ chế LOGICAL_CLOCK cho phép các Worker Thread trên Slave áp dụng các transaction độc lập song song với nhau, miễn là chúng không xung đột. Đây là cấu hình tối ưu để giảm Lag:
SET GLOBAL slave_parallel_type = 'LOGICAL_CLOCK'; -- Kích hoạt Parallel Replication theo cơ chế Logical Clock
SET GLOBAL slave_parallel_workers = 16; -- Thiết lập số lượng worker song song
SET GLOBAL slave_preserve_commit_order = ON; -- Đảm bảo thứ tự commit của các worker được bảo toàn
SET GLOBAL slave_pending_jobs_size_max = 536870912; -- Ví dụ: 512MBTối ưu Replication Lag
Các long-running transactions trên Master là nguyên nhân chính gây bottleneck cho Parallel Replication, khiến Slave bị lag.
Anh em cần giám sát để xác định và tối ưu các transaction này, yêu cầu team Dev chia nhỏ chúng hoặc chuyển sang chạy Batch Job vào giờ thấp điểm.
-- Truy vấn giám sát các transaction đang chạy quá 1 giây trên Master
SELECT
thread_id,
processlist_id,
trx_started,
trx_rows_modified,
trx_rows_locked
FROM performance_schema.events_transactions_current
WHERE state = 'ACTIVE'
AND timer_wait > 1000000000000 -- Lớn hơn 1 giây
ORDER BY timer_wait DESC;Xây dựng hệ thống mornitoring
Giám sát trong kiến trúc Master-Slave không chỉ là kiểm tra server còn sống hay không. Nó là việc đo lường tình trạng toàn diện của Replication và hiệu năng. Chúng ta cần thiết lập Prometheus + Grafana để theo dõi các chỉ số sau một cách chủ động.
View sau đây tổng hợp các thông tin quan trọng nhất từ cả hai nguồn GLOBAL_VARIABLES và performance_schema (hoặc SHOW SLAVE STATUS), giúp công cụ Monitoring (như Prometheus Exporter) pull data hiệu quả.
-- Tạo View giám sát trạng thái Master/Slave (Dùng trên Slave)
CREATE OR REPLACE VIEW replication_monitor_status AS
SELECT
@@server_id AS server_id,
@@hostname AS hostname,
CASE
WHEN @@read_only = 0 THEN 'MASTER'
ELSE 'SLAVE'
END AS role,
-- Lấy các chỉ số từ SHOW SLAVE STATUS (hoặc dùng performance_schema trên 8.0+)
(SELECT Seconds_Behind_Master FROM performance_schema.replication_group_members) AS replication_lag_seconds,
(SELECT Service_State FROM performance_schema.threads WHERE NAME = 'thread/sql/slave_io') AS io_thread_state,
(SELECT Service_State FROM performance_schema.threads WHERE NAME = 'thread/sql/slave_sql') AS sql_thread_state;
-- Lưu ý: Trong môi trường thực, các công cụ Monitoring thường dùng SHOW SLAVE STATUS\G
-- hoặc các Metrics riêng của MySQL Exporter để lấy dữ liệu này trực tiếp.Việc thiết lập Monitoring phải đảm bảo chuẩn hóa và có dashboard, giúp anh em vận hành có thể nhìn nhanh và đưa ra quyết định kịp thời.
Xử lý Sự cố Replication thường gặp
Trong quá trình vận hành, Replication bị gián đoạn là điều không thể tránh khỏi. Dưới đây là các lỗi phổ biến và giải pháp khắc phục.
Duplicate Key Error
Nguyên nhân: Thường xảy ra khi một thao tác ghi (INSERT/UPDATE) bị thực hiện trực tiếp trên Slave, hoặc do lỗi logic khiến Master và Slave sinh ra dữ liệu Primary Key trùng nhau (thường xảy ra nếu không dùng GTID hoặc auto_increment_offset).
Thông báo lỗi thường thấy: Last_SQL_Error: Error 'Duplicate entry '12345' for key 'PRIMARY'' on query...
Giải pháp tạm thời:
STOP SLAVE;
SET GLOBAL SQL_SLAVE_SKIP_COUNTER = 1; -- Bỏ qua sự kiện lỗi
START SLAVE;Giải pháp triệt để:
- Kiểm tra lại cấu hình Slave: bắt buộc phải bật
read_only = ONvàsuper_read_only = ON. - Nếu phải dùng
SQL_SLAVE_SKIP_COUNTER, cần kiểm tra tính nhất quán dữ liệu sau đó. Nếu cần, xóa bản ghi lỗi trên Slave để Replication có thể tiếp tục.
Test code và sửa lỗi dữ liệu (thủ công):
STOP SLAVE;
-- Kiểm tra bản ghi lỗi trên Slave
SELECT * FROM <tên_bảng_gây_lỗi> WHERE <khóa_chính> = '12345';
-- 3. Xóa bản ghi lỗi trên Slave để dọn đường cho lệnh mới từ Master
DELETE FROM <tên_bảng_gây_lỗi> WHERE <khóa_chính> = '12345';
START SLAVE;Primary Key Conflicts
Nếu không sử dụng GTID hoặc trong kiến trúc Multi-Master, việc định cấu hình lại auto increment step/offset là cần thiết để đảm bảo các server không tạo ra ID trùng nhau.
-- Thiết lập step là 2, Offset bắt đầu cho Master là 1
-- Master (ví dụ: 1, 3, 5, 7...)
SET GLOBAL auto_increment_increment = 2;
SET GLOBAL auto_increment_offset = 1;
-- Thiết lập step là 2, Offset bắt đầu cho Slave là 2
-- Slave (ví dụ: 2, 4, 6, 8...)
SET GLOBAL auto_increment_increment = 2;
SET GLOBAL auto_increment_offset = 2;Kiểm tra tính nhất quán dữ liệu
Trong môi trường Production, việc kiểm tra định kỳ để đảm bảo dữ liệu Master và Slave khớp nhau là điều bắt buộc.
Code ví dụ về Stored Procedure kiểm tra thủ công:
-- Thủ tục kiểm tra số lượng bản ghi giữa Master và Slave
DELIMITER $$
CREATE PROCEDURE check_table_count(
IN p_table_name VARCHAR(64)
)
BEGIN
DECLARE v_master_count BIGINT;
SET @sql_count = CONCAT('SELECT COUNT(*) INTO @master_count FROM ', p_table_name);
PREPARE stmt_count FROM @sql_count;
EXECUTE stmt_count;
DEALLOCATE PREPARE stmt_count;
-- Kết quả trả về (thường được so sánh với số lượng trên Slave)
SELECT p_table_name AS table_name, @master_count AS row_count;
END$$
DELIMITER ;
-- Sử dụng công cụ pt-table-checksum của Percona Toolkit để kiểm tra checksum chi tiết.Best Practices ở level doanh nghiệp
Trong môi trường Production, việc đảm bảo tính ổn định và an toàn của cơ sở dữ liệu đòi hỏi chúng ta phải tuân thủ các nguyên tắc thiết kế và quy trình vận hành đã được chuẩn hóa.
Nguyên tắc thiết kế kiến trúc
Kiến trúc Master-Slave phải được thiết kế để chịu lỗi fault tolerance và đạt được tính HA.
- Loại bỏ SPOF: Triển khai tính redundancy cho mọi thành phần, sử dụng failover tự động (MHA/GR) cần được kiểm thử định kỳ.
- Giám sát ưu tiên tuyệt đối: Đảm bảo 100% Monitoring Coverage, thiết lập ngưỡng cảnh báo dựa trên Baseline hiệu suất.
- Bảo toàn Dữ liệu là yếu tố cốt lõi: Kích hoạt
sync_binlog = 1trên Master và ưu tiên cơ chế Semi-synchronous Replication để đảm bảo RPO gần bằng 0.
Tiêu chuẩn vận hành
Quy trình vận hành phải được chuẩn hóa thành Checklist để tránh rủi ro do lỗi thao tác thủ công.
# Danh sách kiểm tra vận hành Production
production_operation_checklist:
# Các bước bắt buộc trước khi triển khai/thay đổi
before_operation:
- check_business_peak_time: "Tránh mọi thao tác thay đổi trong giờ cao điểm của nghiệp vụ."
- backup_current_data: "Thực hiện Full Backup và kiểm tra tính toàn vẹn của Backup."
- prepare_rollback_plan: "Xây dựng kịch bản Rollback chi tiết, đã được kiểm tra."
- notify_stakeholders: "Thông báo tới các bên liên quan (App, QA, Business) về kế hoạch và thời gian."
# Các bước trong quá trình thực hiện
during_operation:
- monitor_key_metrics: "Giám sát thời gian thực các chỉ số quan trọng (QPS, Lag) trên màn hình Dashboard chuyên dụng."
- record_operation_log: "Ghi lại nhật ký thao tác chi tiết, bao gồm thời gian và lệnh đã thực thi."
- test_step_by_step: "Xác minh kết quả của từng bước trước khi chuyển sang bước tiếp theo."
# Các bước sau khi hoàn thành thay đổi
after_operation:
- verify_data_consistency: "Kiểm tra tính nhất quán dữ liệu và trạng thái Replication cuối cùng."
- check_application_function: "Phối hợp với team Dev/QA kiểm tra lại chức năng của ứng dụng."
- update_documentation: "Cập nhật tài liệu kiến trúc, cấu hình ngay lập tức."Security Hardening
-- 1. Áp dụng nguyên tắc đặc quyền tối thiểu (Least Privilege)
-- User chỉ có quyền Đọc
CREATE USER 'app_read'@'10.0.0.%' IDENTIFIED BY 'ReadOnly@';
GRANT SELECT ON production.* TO 'app_read'@'10.0.0.%';
-- User có quyền Đọc-Ghi
CREATE USER 'app_write'@'10.0.0.%' IDENTIFIED BY 'WriteUser@';
GRANT SELECT, INSERT, UPDATE, DELETE ON production.* TO 'app_write'@'10.0.0.%';
-- 2. Bật Audit Logging
SET GLOBAL audit_log_file = '/var/log/mysql/audit.log';
SET GLOBAL audit_log_format = 'JSON';
SET GLOBAL audit_log_policy = 'ALL';Lời Kết
Không có kiến trúc tốt nhất, chỉ có kiến trúc phù hợp nhất. Tuy nhiên, những nguyên tắc về HA, RPO=0, GTID và tối ưu Parallel Replication là nền tảng mà anh em phải tuân thủ để xây dựng một hệ thống Database chịu tải và sẵn sàng cao.




















