Lướt một vòng xem tuần này có gì hay ho thì mình thấy được kinh nghiệm khá hay ho.
Đầu tiên là xem cách Tinder dùng HTTP Live Streaming (HLS) để phục vụ hàng triệu người dùng. Sau đó, sẽ đào sâu một chút về Replication trong Database phân tán, tóm tắt từ chương 5 của cuốn sách thần thánh Designing Data Intensive Applications. Cuối cùng là vài mẩu tin vặt và một câu hỏi phỏng vấn.
Tinder dùng HTTP Live Streaming (HLS) để stream video như thế nào?
Tinder, với hơn 75 triệu người dùng hoạt động hàng tháng, không chỉ là app quẹt trái quẹt phải. Họ có một tính năng tên là Swipe Night, một dạng game phiêu lưu tương tác ngay trong app. Mọi người sẽ xem các đoạn video ngắn và đưa ra lựa chọn, từ đó Tinder sẽ gợi ý match dựa trên các lựa chọn đó.
Thử thách ở đây là: tất cả người dùng xem video cùng một lúc, vào một giờ cố định (6 giờ tối, giờ địa phương). Shreyas Hirday, một kỹ sư phần mềm senior ở Tinder, đã có một bài blog chia sẻ về công nghệ họ đã dùng.
Đây là tóm tắt của tôi:
Mục tiêu của Tinder khi làm tính năng này là:
- Dynamic: Có thể thay đổi nội dung video bất cứ lúc nào.
- Efficient: Giảm thiểu sử dụng bộ nhớ vì app chạy trên điện thoại.
- Seamless: Video phải chạy trơn tru, không giật lag.
Dựa trên các mục tiêu đó, Tinder quyết định chọn HTTP Live Streaming (HLS), một giao thức adaptive bitrate do Apple phát triển.
Nói nôm na, adaptive bitrate streaming có nghĩa là server sẽ chuẩn bị sẵn nhiều phiên bản của cùng một video, mỗi phiên bản có resolution và bitrate khác nhau. Video player trên điện thoại sẽ tự động chọn phiên bản phù hợp nhất dựa vào kích thước màn hình và tốc độ mạng của người dùng. Mạng yếu thì xem bản chất lượng thấp hơn một chút để không bị buffering, mạng mạnh thì cứ max settings mà triển.
Transcoding
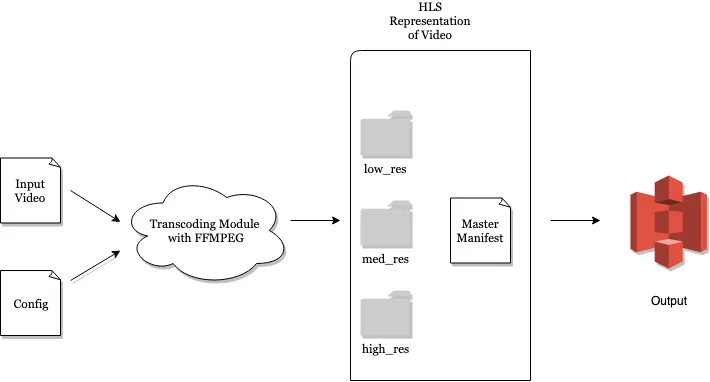
Team Tinder dùng FFMPEG, một công cụ mã nguồn mở cực mạnh, để chuyển đổi file MP4 gốc sang định dạng HLS stream. Đầu vào là file MP4 và các file config (resolution, bitrate, frame rate…), đầu ra là một thư mục chứa HLS stream hoàn chỉnh.
Tất cả các phiên bản video này được lưu trên AWS S3.
Validation
Đầu ra của HLS stream sẽ có một file kê khai gọi là “Master Manifest”. File này chứa thông tin về tất cả các phiên bản video. Video player sẽ đọc file này để biết file nào.
Vì vậy, file manifest này phải cực kỳ chính xác. Apple cung cấp một công cụ tên là Media Stream Validator để kiểm tra file manifest bằng cách giả lập quá trình streaming. Tinder dùng tool này để đảm bảo mọi thứ ngon lành trước khi đẩy lên production.
Content Access & Delivery
Để đảm bảo người dùng trên toàn thế giới có trải nghiệm mượt mà, độ trễ thấp, Tinder dùng AWS Cloudfront, một dịch vụ mạng phân phối nội dung (CDN). Khi người dùng ở một khu vực nào đó bắt đầu xem Swipe Night, CDN sẽ tự động copy HLS stream từ S3 về các cache ở gần khu vực đó.
Đo lường hiệu năng video (KPIs)
Tinder dùng 5 chỉ số hiệu năng (KPI) chính để đo lường:
- Thời gian chờ ban đầu để video bắt đầu chạy.
- Số lần bị stalls trong lúc xem.
- Tổng thời gian bị đứng hình.
- Tỷ lệ % các phiên xem video bị lỗi.
- Chất lượng video trung bình được đo bằng bitrate trung bình.
Họ phải tìm cách cân bằng 5 chỉ số này. Ví dụ, với một app như Netflix, chờ buffer 5 giây có thể chấp nhận được. Nhưng trên một app di động như Tinder, 5 giây buffer có thể khiến người dùng bực mình và thoát app ngay lập tức.
Tech Snippets
- xây dựng 10 web app… với 10 ngôn ngữ khác nhau: Jeff Delaney đã có một bài tổng quan cực hay về 10 web framework khác nhau, từ Ruby on Rails, Django (Python), Laravel (PHP), đến NextJS (JavaScript), Spring (Java),… Theo anh, Ruby on Rails cho trải nghiệm phát triển tốt nhất.
- Bán hơn 600 bản sách kỹ thuật tự xuất bản: Josef Strzibny, một kỹ sư phần mềm, đã viết cuốn sách Deployment from Scratch và kiếm được hơn 24.000 đô la. Anh chia sẻ toàn bộ quá trình và phân tích doanh thu trong bài blog của mình.
- Tìm hiểu sâu về Hadoop Distributed File System (HDFS): Một bài viết tuyệt vời mô tả kiến trúc của HDFS và kinh nghiệm sử dụng nó để quản lý 40 petabyte dữ liệu tại Yahoo!
Cách hoạt động của Database Replication
Designing Data Intensive Applications (DDIA) là cuốn sách gối đầu giường cho bất kỳ ai làm backend. Dưới đây là tóm tắt nhanh của tôi về Chương 5, nói về Replication.
Replication là việc mọi người giữ bản sao dữ liệu của mình trên nhiều máy khác nhau, kết nối qua mạng. Thay vì một database duy nhất, giờ mọi người có một distributed database.
Tại sao phải làm vậy?
- Latency: Người dùng ở Việt Nam có thể truy vấn data từ node ở Singapore, thay vì phải gọi tới tận Mỹ.
- Availability: Nếu một node chết, vẫn còn các node khác để phục vụ.
- Read Throughput: Nhiều node có thể cùng lúc trả lời các truy vấn đọc, giảm tải cho hệ thống.
Cái khó của replication nằm ở việc xử lý khi dữ liệu thay đổi. Làm sao để khi có một request WRITE, tất cả các replica đều được cập nhật?
Có 3 chiến lược phổ biến:
- Single Leader Replication: Một node được chỉ định làm leader. Mọi request
WRITEđều phải đi qua leader. Leader sau đó sẽ truyền bá thay đổi này đến các node follower. Đây là chiến lược được dùng bởi PostgreSQL, MongoDB, MySQL,… - Multi Leader Replication: Tương tự Single Leader, nhưng có thể có nhiều node làm leader và nhận request
WRITE. - Leaderless Replication: Tất cả các node đều có thể nhận request
WRITE, không có khái niệm leader. Cassandra và Riak là ví dụ điển hình.
Single Leader là chiến lược phổ biến nhất, nên chúng ta sẽ tìm hiểu sâu hơn về nó.
Cơ chế của Single Leader Replication
- Một replica được chọn làm leader. Client gửi request
WRITEđến leader. - Các replica còn lại là follower. Leader sau khi ghi dữ liệu mới vào local storage của mình, nó sẽ gửi thay đổi này cho tất cả follower.
- Khi client muốn đọc dữ liệu, request
READcó thể được gửi đến bất kỳ node nào, cả leader và follower.
Việc ghi dữ liệu có thể là asynchronous hoặc synchronous.
- Với asynchronous write, leader ghi xong phần mình là trả lời client “OK!” ngay. Sau đó nó mới gửi thay đổi cho các follower. Cách này nhanh nhưng có rủi ro mất dữ liệu nếu leader chết trước khi kịp gửi thay đổi.
- Với synchronous write, leader phải chờ cho đến khi tất cả follower xác nhận đã ghi xong rồi mới báo “OK!” cho client. Cách này an toàn nhưng rất chậm.
Trong thực tế, người ta thường dùng asynchronous hoặc semi-synchronous (chờ một số lượng follower nhất định xác nhận).
Các vấn đề thường gặp với Single Leader
-
Node Outages:
- Follower chết: Dễ xử lý. Khi follower sống lại, nó sẽ hỏi leader những thay đổi đã xảy ra trong lúc nó ngủm và tự cập nhật lại.
- Leader chết: Phức tạp hơn. Phải bầu một follower lên làm leader mới. Quá trình này gọi là failover. Failover có thể gây ra nhiều vấn đề, ví dụ như split brain (leader cũ sống lại và vẫn nghĩ mình là leader).
-
Replication Lag
- Vì các follower cập nhật không đồng thời, sẽ có lúc dữ liệu ở follower bị cũ hơn so với leader. Hiện tượng này gọi là eventual consistency (rồi cuối cùng cũng sẽ nhất quán).
- Tuy nhiên, độ trễ này có thể gây ra trải nghiệm tệ cho người dùng.
Giải pháp cho Replication Lag
- Read Your Own Writes: Đảm bảo người dùng luôn thấy được những thay đổi mà chính họ vừa thực hiện. Ví dụ, bạn vừa đăng tweet, refresh lại trang phải thấy tweet của mình ngay. Cách triển khai: trong một khoảng thời gian ngắn sau khi user
WRITE, mọi requestREADcủa user đó sẽ được điều hướng đến leader. - Monotonic Reads: Tránh tình trạng người dùng refresh trang và thấy dữ liệu bị quay ngược thời gian (lần refresh sau lại thấy dữ liệu cũ hơn lần trước). Cách giải quyết: đảm bảo mỗi user luôn đọc từ cùng một follower (có thể hash User ID để chọn follower).
- Consistent Prefix Reads: Đảm bảo các sự kiện có quan hệ nhân quả được thấy theo đúng thứ tự. Ví dụ, nếu bạn thấy câu trả lời của B cho tweet của A, bạn phải thấy được tweet của A trước.
Trên đây là nội dung mình lướt thấy có khá nhiều thứ có thể học được từ substack.









