
Chào mọi người,
Trong kỷ nguyên của microservices, kiến trúc phân tán hay các hệ thống cloud-native phức tạp như hiện nay, việc “biết rõ chuyện gì đang xảy ra bên trong hệ thống của mình” không còn là một điều xa xỉ, mà là một yêu cầu sống còn. Khái niệm giám sát (monitoring) truyền thống đang dần nhường chỗ cho một phương pháp tiếp cận mạnh mẽ hơn: Quan sát được (Observability).

Hôm nay, mình muốn cùng mọi người đi sâu vào việc thiết kế và xây dựng một Hệ thống Giám sát Toàn diện (Observability Stack). Chúng ta sẽ cùng nhau tìm hiểu sự khác biệt giữa Monitoring và Observability, và quan trọng hơn, cách kết hợp ba trụ cột chính – Metrics, Logs và Traces – để có được cái nhìn sâu sắc và có thể hành động được về hiệu suất và sức khỏe “đứa con” hệ thống của chúng ta.
I. Monitoring vs. Observability: Khác Biệt Một Trời Một Vực?
Trước khi bắt đầu hành trình xây dựng “tháp giám sát” này, mình muốn mọi người cùng làm rõ hai khái niệm mà rất nhiều người thường nhầm lẫn nhé:
- Giám sát (Monitoring): Mọi người hình dung thế này, Monitoring giống như việc bạn có một bảng điều khiển ô tô với các đèn cảnh báo đã được định nghĩa sẵn: đèn báo xăng, đèn báo dầu, đèn báo nhiệt độ động cơ. Bạn biết những chỉ số này là quan trọng và bạn theo dõi chúng. Monitoring giúp bạn biết khi nào có vấn đề (ví dụ: đèn báo dầu sáng). Nó tập trung vào việc theo dõi những gì đã biết trước (known-unknowns).
- Quan sát được (Observability): Còn Observability thì sao? Nó giống như việc bạn không chỉ có bảng điều khiển, mà còn có cả một bộ công cụ chẩn đoán chuyên sâu, cho phép bạn “mổ xẻ” động cơ, lắng nghe từng tiếng động lạ, kiểm tra từng dòng khí thải để hiểu tại sao chiếc xe lại có vấn đề, ngay cả khi không có đèn báo nào sáng. Observability giúp chúng ta xử lý những vấn đề chưa biết trước (unknown-unknowns). Nó là khả năng truy vấn, phân tích và tương quan các loại dữ liệu khác nhau để hiểu sâu về trạng thái bên trong.
Vậy, tại sao Observability lại quan trọng đến vậy? Với những hệ thống microservices phức tạp, nơi hàng trăm dịch vụ nhỏ “nói chuyện” với nhau, việc chỉ nhìn vào các đèn báo hay điểm cuối không còn đủ nữa. Một lỗi nhỏ ở một dịch vụ có thể gây ra “hiệu ứng domino” trên toàn bộ hệ thống. Observability chính là “chiếc kính lúp” và “bộ công cụ điều tra” giúp chúng ta nhanh chóng xác định và khắc phục sự cố trong môi trường phức tạp này.
II. Ba Trụ Cột Vững Chắc của Observability
Observability được xây dựng trên ba loại dữ liệu telemetry chính, thường được gọi là “Ba Trụ Cột”. Mình sẽ giải thích từng trụ cột một cách dễ hiểu nhất:
1. Metrics (Chỉ số)
- Chúng là gì? Metrics là những con số được thu thập và tổng hợp theo thời gian. Chúng có cấu trúc rất rõ ràng, giống như các cột số liệu trong một bảng tính Excel vậy.
- Ví dụ thực tế:
- Hệ thống: CPU đang dùng bao nhiêu %, bộ nhớ còn bao nhiêu GB, tốc độ mạng ra/vào là bao nhiêu.
- Ứng dụng: Số lượng yêu cầu (request) nhận được mỗi giây (RPS), độ trễ trung bình của các yêu cầu, tỷ lệ lỗi HTTP 5xx.
- Vai trò trong Observability: Metrics cho chúng ta cái nhìn tổng quan, giúp mình nhanh chóng thấy được khi nào có vấn đề và ở đâu (dịch vụ nào, pod nào). Chúng là điểm khởi đầu tuyệt vời cho mọi cuộc điều tra.
- Công cụ phổ biến:
- Prometheus: Đây là “bộ não” để thu thập và lưu trữ các chỉ số thời gian thực (time-series metrics).
- Grafana: “Đôi mắt” của chúng ta, giúp mình tạo ra các dashboard đẹp mắt, trực quan để nhìn thấy dữ liệu từ Prometheus.
- Datadog, New Relic, Dynatrace: Đây là các giải pháp thương mại “tất cả trong một”, cung cấp cả metrics và nhiều tính năng khác.
2. Logs (Nhật ký)
- Chúng là gì? Logs là các bản ghi sự kiện rời rạc, thường là các dòng văn bản ghi lại những gì đã xảy ra tại một thời điểm cụ thể. Chúng có thể có cấu trúc hoặc không có cấu trúc.
- Ví dụ thực tế:
- “Người dùng
nguyenvanavừa đăng nhập từ địa chỉ IP192.168.1.10.” - “Lỗi xử lý đơn hàng
DN001: Không kết nối được cơ sở dữ liệu.” - “API POST
/productstrả về 200 OK trong 50ms.”
- “Người dùng
- Vai trò trong Observability: Nếu metrics cho mình biết “có gì đó không ổn”, thì logs cung cấp ngữ cảnh và thông tin chi tiết về tại sao nó lại không ổn. Khi metrics chỉ ra một sự cố, logs giúp mình đào sâu để tìm ra nguyên nhân gốc rễ.
- Công cụ phổ biến:
- ELK Stack (Elasticsearch, Logstash, Kibana): Một bộ ba mã nguồn mở “thần thánh” để thu thập, phân tích, lưu trữ và hình ảnh hóa logs.
- Loki (của Grafana Labs): Một hệ thống tổng hợp logs được thiết kế để hoạt động “ăn ý” với Prometheus và Grafana, tập trung vào việc lưu trữ logs hiệu quả về chi phí.
- Fluentd/Fluent Bit: Giống như những “chú ong chăm chỉ” thu thập và chuyển tiếp logs từ các ứng dụng của mình.
3. Traces (Dấu vết / Truy vết)
- Chúng là gì? Traces là “hành trình” của một yêu cầu duy nhất khi nó “chu du” qua nhiều dịch vụ hoặc thành phần trong một hệ thống phân tán. Mỗi hoạt động nhỏ trong hành trình đó được gọi là một “span”.
- Ví dụ thực tế: Khi một yêu cầu đặt hàng của khách hàng đến hệ thống, nó có thể đi qua: Cổng API (API Gateway) -> Dịch vụ xác thực -> Dịch vụ giỏ hàng -> Dịch vụ thanh toán -> Cơ sở dữ liệu. Trace sẽ cho mình thấy mỗi bước mất bao nhiêu thời gian, và nếu có lỗi, nó xảy ra ở bước nào.
- Vai trò trong Observability: Cực kỳ quan trọng trong kiến trúc microservices. Traces giúp mình hiểu được làm thế nào các dịch vụ tương tác với nhau và ở đâu độ trễ hoặc lỗi phát sinh trong luồng xử lý của một yêu cầu cụ thể.
- Công cụ phổ biến:
- Jaeger / Zipkin: Hai hệ thống truy vết phân tán mã nguồn mở phổ biến.
- OpenTelemetry: Đây là một dự án của Cloud Native Computing Foundation (CNCF) đang phát triển để chuẩn hóa việc tạo và thu thập cả ba loại telemetry (metrics, logs, traces) từ ứng dụng của bạn. Đây là tiêu chuẩn đang được khuyến nghị sử dụng.
III. Thiết Kế Hệ Thống Observability Stack: Cùng Bắt Tay Vào Làm!
Việc thiết kế một Observability Stack hiệu quả đòi hỏi mình phải xem xét kỹ lưỡng về kiến trúc, công cụ và quy trình.
Bước 1: Xác Định Yêu Cầu và Mục Tiêu Của Mình
Trước khi “vung tay” cài đặt, hãy tự hỏi:
- Ai sẽ dùng hệ thống này? (Developer, Ops, Business Analyst)
- Mình cần quan sát cái gì? (Kubernetes, Serverless, VMs, Monolith, Microservices)
- Mình muốn lưu trữ dữ liệu trong bao lâu? (Ví dụ: metrics 1 năm, logs 30 ngày, traces 7 ngày)
- Ngân sách bao nhiêu? Khả năng mở rộng thế nào?
- Có yêu cầu bảo mật hay tuân thủ nào không?
- Các chỉ số độ tin cậy (SLI/SLO) quan trọng của mình là gì?
Bước 2: Lựa Chọn “Vũ Khí” (Công Cụ) và Kiến Trúc
Đây là phần trung tâm. Mình sẽ giới thiệu hai kiến trúc phổ biến:
A. Stack Mã Nguồn Mở (Ưu tiên CNCF):
Đây là lựa chọn lý tưởng cho những ai thích sự linh hoạt, kiểm soát và cộng đồng lớn mạnh.
- Metrics: Prometheus + Grafana (có thể dùng thêm Cortex/Thanos để mở rộng quy mô lớn)
- Logs: Loki + Grafana (hoặc nếu thích mạnh mẽ và phân tích sâu hơn thì ELK Stack: Elasticsearch, Logstash, Kibana)
- Traces: Jaeger (hoặc Zipkin) + OpenTelemetry Collector
- Thu thập dữ liệu: Prometheus Node Exporter (cho metrics hệ thống), cAdvisor (cho metrics container), Fluentd/Fluent Bit (cho logs), OpenTelemetry SDKs (cho logs, metrics, traces từ ứng dụng).
- Cảnh báo: Alertmanager (từ Prometheus)
Sơ đồ Kiến trúc mẫu:
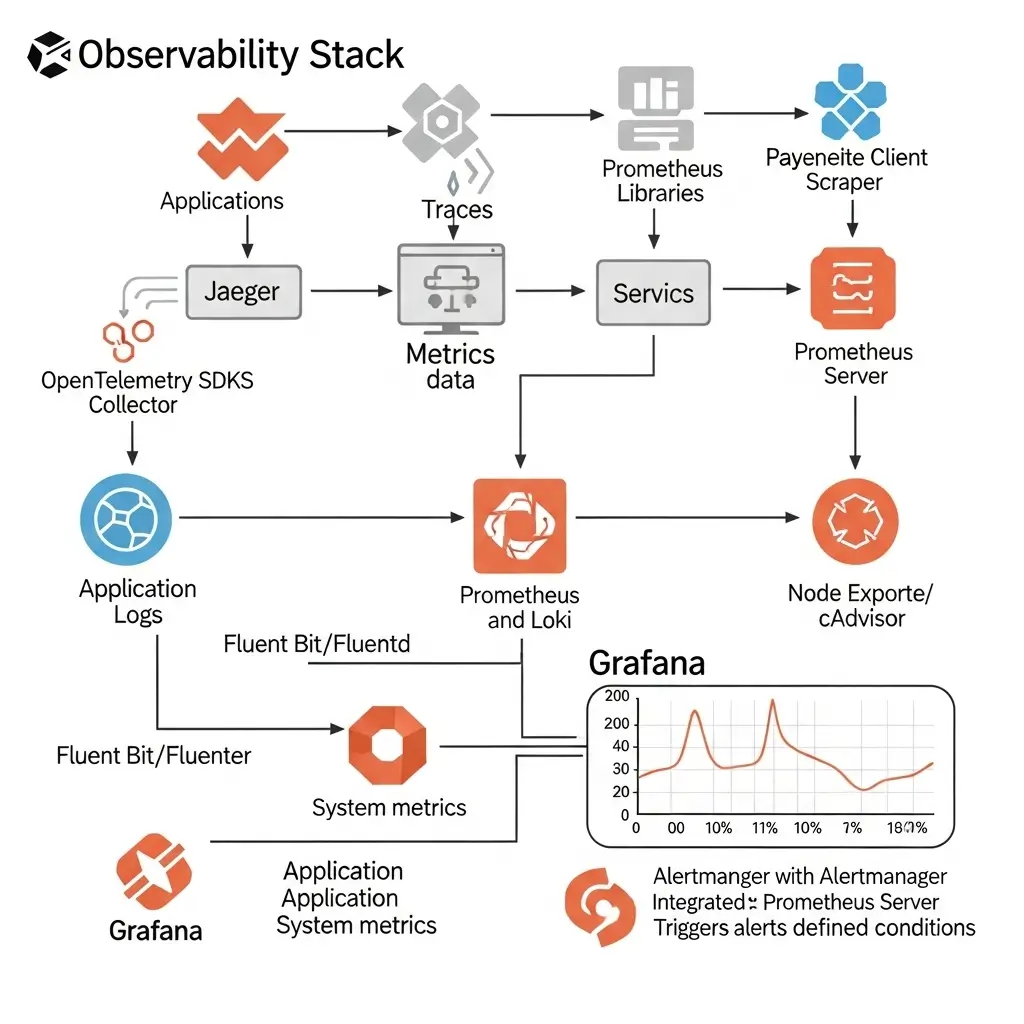
B. Stack Thương Mại (Managed Services):
Đây là lựa chọn “mì ăn liền” cho những ai muốn sự tiện lợi, ít phải quản lý hạ tầng.
- Giải pháp “tất cả trong một”: Datadog, New Relic, Dynatrace, Splunk.
- Ưu điểm: Cài đặt nhanh, tích hợp chặt chẽ, hỗ trợ tốt, không cần tự quản lý server.
- Nhược điểm: Chi phí thường cao hơn, ít linh hoạt hơn trong việc tùy chỉnh sâu.
C. Hybrid Approach: Mình cũng có thể kết hợp cả hai. Ví dụ, dùng Prometheus tự quản lý cho metrics vì nó rất mạnh, nhưng logs thì lại dùng CloudWatch Logs/Azure Monitor Logs của nhà cung cấp dịch vụ đám mây cho tiện.
Bước 3: Triển Khai và Tích Hợp
Đây là lúc “xắn tay áo” vào làm:
-
Instrumenting Applications (Thêm “ống nghe” vào ứng dụng): Đây là bước quan trọng nhất đó!
- Metrics: Mọi người hãy dùng các thư viện client của Prometheus (hoặc OpenTelemetry) để xuất ra các metrics tùy chỉnh từ trong code của mình.
- Logs: Đảm bảo ứng dụng ghi logs có cấu trúc (JSON là tốt nhất) và xuất ra
stdout/stderr(đặc biệt trong môi trường container). - Traces: Tích hợp các SDK của OpenTelemetry vào code. Điều này sẽ giúp tự động tạo ra các “span” và truyền “context” (ví dụ: trace ID) qua các dịch vụ.
Ví dụ Code (Python Flask):
# app.py - Ví dụ ứng dụng Flask với Prometheus metrics và OpenTelemetry Tracing from flask import Flask, request, jsonify from prometheus_client import generate_latest, Counter, Histogram from opentelemetry import trace from opentelemetry.instrumentation.flask import FlaskInstrumentor from opentelemetry.sdk.trace import TracerProvider from opentelemetry.sdk.trace.export import ConsoleSpanExporter, BatchSpanProcessor from opentelemetry.sdk.resources import Resource # Khởi tạo OpenTelemetry Tracer resource = Resource.create({"service.name": "my-observability-app"}) provider = TracerProvider(resource=resource) processor = BatchSpanProcessor(ConsoleSpanExporter()) # In trace ra console, thực tế gửi đến Jaeger provider.add_span_processor(processor) trace.set_tracer_provider(provider) tracer = trace.get_tracer(__name__) app = Flask(__name__) FlaskInstrumentor().instrument_app(app) # Tự động instrument Flask # Prometheus Metrics REQUEST_COUNT = Counter( 'app_request_count', 'Total number of requests', ['method', 'endpoint'] ) REQUEST_LATENCY = Histogram( 'app_request_latency_seconds', 'Request latency in seconds', ['method', 'endpoint'] ) @app.route('/') def hello_world(): REQUEST_COUNT.labels(method='GET', endpoint='/').inc() with REQUEST_LATENCY.labels(method='GET', endpoint='/').time(): return "Hello, Observability!" @app.route('/api/process_order', methods=['POST']) def process_order(): current_span = trace.get_current_span() current_span.set_attribute("order.id", request.json.get("order_id")) # Giả lập một số logic và tương tác dịch vụ khác with tracer.start_as_current_span("db_lookup") as span: span.set_attribute("db.query", "SELECT * FROM orders WHERE id = ...") # Giả lập độ trễ DB import time time.sleep(0.05) print("DB lookup completed.") # Đây sẽ là một dòng log REQUEST_COUNT.labels(method='POST', endpoint='/api/process_order').inc() with REQUEST_LATENCY.labels(method='POST', endpoint='/api/process_order').time(): order_id = request.json.get('order_id', 'N/A') print(f"Processing order: {order_id}") # Đây sẽ là một dòng log return jsonify({"status": "Order processed", "order_id": order_id}), 200 @app.route('/metrics') def metrics(): return generate_latest(), 200, {'Content-Type': 'text/plain'} if __name__ == '__main__': app.run(debug=True, host='0.0.0.0', port=5000)Để chạy ví dụ trên:
- Cài đặt:
pip install Flask prometheus_client opentelemetry-api opentelemetry-sdk opentelemetry-instrumentation-flask - Chạy:
python app.py - Thử nghiệm:
- Mở trình duyệt:
http://localhost:5000 - Gửi POST request:
curl -X POST -H "Content-Type: application/json" -d '{"order_id": "ORD123"}' http://localhost:5000/api/process_order - Xem metrics:
http://localhost:5000/metricsMọi người sẽ thấy logs và trace spans in ra console (nếu dùng Jaeger thật, nó sẽ gửi đến Jaeger Collector).
- Mở trình duyệt:
-
Deploying Collectors/Agents: Cài đặt các “người thu thập” dữ liệu (Prometheus Node Exporter, Fluent Bit, OpenTelemetry Collector) trên các máy chủ, Kubernetes nodes hoặc dưới dạng sidecar containers bên cạnh ứng dụng của mình.
-
Configuring Backend Systems: Cài đặt và cấu hình Prometheus, Loki, Jaeger.
-
Thiết lập CI/CD: Đảm bảo việc thêm “ống nghe” (instrumentation) là một phần của quy trình phát triển và triển khai của mình.
Bước 4: Xây Dựng Dashboards và Cảnh Báo
- Dashboard:
- Tạo ra các dashboard trực quan trong Grafana (hoặc công cụ tương tự) để hiển thị các metrics quan trọng.
- Hãy tập trung vào “Golden Signals” (Tốc độ (Latency), Lượng truy cập (Traffic), Lỗi (Errors), Mức độ bão hòa (Saturation)) cho từng dịch vụ.
- Xây dựng dashboard theo từng cấp độ: Tổng quan hệ thống -> Sức khỏe dịch vụ -> Chi tiết từng instance của dịch vụ.
- Alerting (Cảnh báo):
- Thiết lập cảnh báo dựa trên các ngưỡng metrics quan trọng (ví dụ: độ trễ tăng đột biến, tỷ lệ lỗi vượt quá giới hạn).
- Sử dụng Alertmanager (cho Prometheus) để gửi cảnh báo đến các kênh mà đội của mình đang dùng (Slack, PagerDuty, Email, v.v.).
- Điều quan trọng là cảnh báo phải “có thể hành động” và cung cấp đủ ngữ cảnh để mọi người phản ứng ngay. Đừng để bị “ngập” trong các cảnh báo rác nhé!
Bước 5: Duy Trì và Tối Ưu Hóa
Việc xây dựng xong không phải là hết đâu, mọi người cần phải:
- Đánh giá định kỳ: Thường xuyên xem xét lại các metrics, logs và traces mà mình đang thu thập. Có cần thêm gì không? Cái gì không còn cần thiết nữa thì bỏ đi để đỡ tốn tài nguyên.
- Quản lý chi phí: Logs và Traces, đặc biệt ở quy mô lớn, có thể “ngốn” khá nhiều tiền đó. Hãy nghĩ đến việc lấy mẫu (sampling) traces, lọc bớt những logs không cần thiết, hoặc lưu trữ logs “nóng” (thường xuyên truy cập) trong thời gian ngắn hơn.
- Training: Đảm bảo toàn bộ đội ngũ phát triển và vận hành của mình đều được đào tạo để sử dụng Observability Stack một cách hiệu quả, không chỉ để xem dashboard mà còn để điều tra sự cố.
- Tự động hóa: Cố gắng tự động hóa việc triển khai và cấu hình các thành phần của Observability thông qua Infrastructure as Code (ví dụ: dùng Terraform để deploy Prometheus, Loki, Grafana).
IV. Thách Thức và Cách Giải Quyết
Trên con đường xây dựng Observability Stack, mình sẽ gặp một số “chướng ngại vật” nho nhỏ:
- Chi phí lưu trữ và xử lý dữ liệu khổng lồ: Logs và traces có thể tạo ra lượng dữ liệu cực lớn.
- Giải pháp: Áp dụng lấy mẫu (sampling) cho traces, lọc bỏ logs không quan trọng, nén dữ liệu, và dùng các giải pháp lưu trữ tối ưu chi phí (ví dụ: object storage cho logs cũ).
- Hiệu năng ứng dụng bị ảnh hưởng khi instrument: Việc thêm code để tạo telemetry có thể làm chậm ứng dụng.
- Giải pháp: Dùng các thư viện đã được tối ưu hóa, tận dụng tính năng tự động instrument (auto-instrumentation) nếu có, và luôn đo lường tác động nhé.
- Truyền ngữ cảnh (Context Propagation) phức tạp: Đảm bảo trace ID được truyền đúng qua tất cả các dịch vụ là một thách thức.
- Giải pháp: Dùng OpenTelemetry và các thư viện hỗ trợ chuẩn W3C Trace Context.
- Bị “ngập” trong cảnh báo (Alert Fatigue): Quá nhiều cảnh báo không cần thiết có thể khiến mình bỏ qua các cảnh báo quan trọng.
- Giải pháp: Tối ưu hóa ngưỡng cảnh báo, chỉ cảnh báo khi thật sự có vấn đề, và đảm bảo cảnh báo cung cấp đủ thông tin để mình hành động.
- Thiếu chuẩn hóa: Mỗi loại telemetry có định dạng và công cụ riêng, việc tương quan có thể khó khăn.
- Giải pháp: Sử dụng OpenTelemetry để chuẩn hóa telemetry, và các công cụ như Grafana để tổng hợp dữ liệu từ nhiều nguồn.
V. Lời Kết
Mọi người thấy đó, một hệ thống Observability Stack được thiết kế tốt là yếu tố then chốt để chúng ta vận hành các hệ thống hiện đại một cách trơn tru. Nó không chỉ giúp mình biết khi nào có vấn đề mà còn tại sao và như thế nào. Bằng cách kết hợp Metrics, Logs và Traces một cách chiến lược, chúng ta sẽ trang bị cho đội ngũ của mình khả năng điều tra, khắc phục sự cố nhanh chóng và liên tục cải thiện độ tin cậy của ứng dụng.
Hãy nhớ rằng, Observability không phải là một sản phẩm mình mua, mà là một thuộc tính mình xây dựng vào hệ thống của mình. Nó là một hành trình liên tục của việc học hỏi, tối ưu hóa và tích hợp.




















.webp "Top nền tảng DAST đáng chú ý năm 2026")