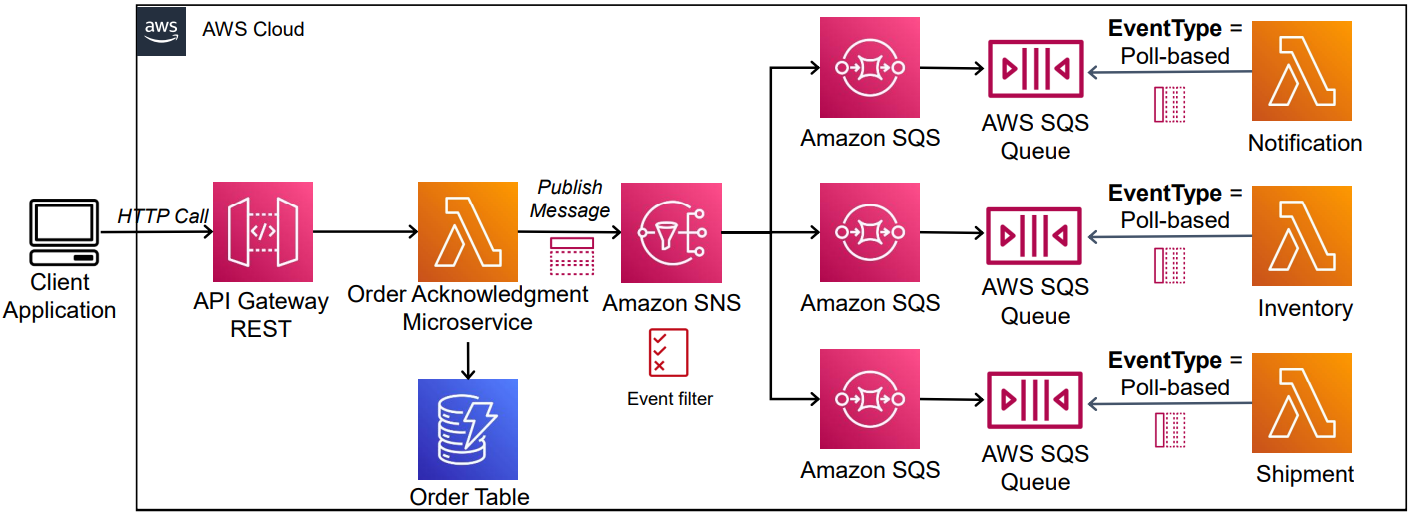
Fan-out architecture thoạt đầu nghe thì đơn giản: một event -> nhiều consumer phản ứng. Nhưng khi hệ thống bước vào quy mô lớn, fan-out không còn là câu chuyện “gửi message cho nhiều nơi”. Lúc này, “nhiều” đồng nghĩa với:

- hàng trăm consumer, hàng triệu event/giây
- multi-region, multi-account, SLO nghiêm ngặt
- hàng chục team scale độc lập, không chờ, không phụ thuộc vào nhau
Ở quy mô này, vấn đề không nằm ở việc publish event, mà nằm ở cách hệ thống chịu lỗi và mở rộng:
- Làm sao khoanh vùng blast radius khi một consumer gặp sự cố?
- Làm sao đảm bảo reliability khi downstream chậm, lỗi, hoặc retry vô hạn?
- Làm sao tránh tự DDoS chính hệ thống của mình khi traffic tăng đột biến?
- Làm sao giữ chi phí ổn định, không bùng nổ theo số consumer?
- Làm sao để từng team có thể scale độc lập?
Fan-out architecture, nếu thiết kế đúng, giải quyết chính những bài toán này. Nếu thiết kế sai, nó sẽ trở thành nguồn gây sự cố dây chuyền, chi phí ngầm, và debug ác mộng.
Bài viết này trình bày một kiến trúc fan-out phổ biến dựa trên SNS + SQS, cùng các pattern và nguyên tắc được xem là best practices khi hệ thống scale traffic.
Bài viết dưới đây rất dài và có nhiều nội dung mang tính chủ quan, được đúc kết từ trải nghiệm cá nhân trong quá trình nghiên cứu về system design và làm việc. Em rất mong nhận được thêm góp ý và chia sẻ từ anh chị và các bạn để ngày càng hoàn thiện hơn. Đồng thời, khuyến khích mọi người chọn lọc, đối chiếu và re-check thông tin từ nhiều nguồn khác nhau, nhằm có được góc nhìn đầy đủ và phù hợp với bối cảnh của riêng mình.
1. Fan-out architecture là gì? Khi nào nên dùng (và khi nào không)
Fan-out architecture là một mô hình event-driven, trong đó một business event được publish một lần và nhiều consumer độc lập subscribe để xử lý những flow khác nhau.
- Producer không biết và không chờ consumer
- Mỗi consumer tự retry, tự fail, tự scale
- Các xử lý phía sau không ràng buộc transaction với nhau
- Business flow chính được giữ gọn, nhanh, ổn định
Fan-out không đơn giản chỉ là “gửi message cho nhiều nơi”. Bản chất của nó là tách toàn bộ xử lý phụ (side-effects) ra khỏi critical path.
Khi nào nên dùng fan-out
- Một business event cần kích hoạt nhiều consumer xử lý độc lập, không cần kết quả ngay
- Mỗi consumer có thể fail độc lập, không kéo sập toàn bộ flow
- Hệ thống cần scale team và scale traffic song song
- Muốn thêm/bớt consumer mà không sửa producer
=> “Nếu một bước lỗi, mình có rollback toàn bộ business flow không?”
Nếu không -> fan-out là lựa chọn tốt.
Khi không nên dùng fan-out
- Cần strong consistency
- Các bước phải chạy theo flow chặt chẽ, bắt buộc rollback nếu bất kỳ bước nào thất bại
- Toàn bộ flow là một transaction logic duy nhất
- Business rule yêu cầu atomicity
=> Trong các trường hợp này, fan-out sẽ làm flow khó kiểm soát và debug phức tạp.
2. Fan-out không thay thế Saga, mà bổ sung cho Saga
Vai trò rõ ràng
- Saga: xử lý critical business flow có thứ tự, cần rollback/compensate (ví dụ AWS Step Functions)
- Fan-out: xử lý side-effects, non-critical, async, eventual consistency (SNS + SQS)
User request
↓
Saga (critical, ordered, rollback) (AWS Step Functions)
↓
Business event published
↓
Fan-out (async, independent, eventually consistent) (AWS SNS + SQS)3. Ví dụ: Event OrderCreated – tách critical và non-critical
Nhóm A – Critical path (có thứ tự, cần consistency)
Các bước bắt buộc thành công để đơn hàng hợp lệ:
- Inventory reserve
- Payment authorize / charge
- Shipping create shipment
- Email “order confirmed” (sau payment)
=> Nhóm này không nên fan-out. Thường dùng Saga Pattern để hoàn thành một business flow.
Nhóm B – Non-critical (chạy song song, eventually consistent)
Các xử lý không ảnh hưởng tính hợp lệ của đơn hàng:
- Analytics / data warehouse
- Audit log
- Search indexing
- Recommendation features
- CRM sync
- Fraud scoring
- Monitoring / anomaly detection
- Cache warming
=> Nhóm này rất phù hợp với fan-out, vì fail cũng không làm “đơn hàng bị sai”.
Nếu nhóm B gọi synchronous thì sao?
- 1 service chậm/lỗi -> toàn flow chậm hoặc rollback dây chuyền
- Thêm service mới -> sửa code producer
- Scale traffic -> bottleneck tập trung
=> Fan-out loại bỏ triệt để các vấn đề này.
4. Vì sao SNS + SQS là lựa chọn fan-out phổ biến
SNS + SQS là cách fan-out đơn giản nhưng đúng hướng, vì nó giải quyết ngay các bài toán cốt lõi:
- Decouple mạnh giữa producer và consumer
- Isolation tuyệt đối: mỗi consumer có một queue riêng
- Retry, DLQ, autoscaling độc lập theo từng consumer
- Vận hành không quá phức tạp, ít state, dễ mở rộng
Saga (critical, ordered, rollback) (AWS Step Functions)
↓
Business event published
↓
SNSTopic(OrderCreated)
↓ ↓ ↓
SQS-A SQS-B SQS-CProducer chỉ publish một lần. Mỗi consumer:
- nhận event qua queue riêng
- xử lý, retry, scale theo nhịp của mình
=> Một consumer chết không ảnh hưởng consumer khác, và không làm chậm critical path.
5. Event là Product – Contract là ranh giới sống còn
Ở quy mô lớn, event không còn là “message nội bộ”. Nó là public API mà nhiều team dùng chung. Producer phát event không biết ai đang subscribe, consumer deploy không đồng bộ, nên contract là ranh giới an toàn duy nhất để hệ thống scale mà không vỡ.
Event ví dụ (contract v1)
{
"event_type": "OrderCreated.v1",
"event_id": "evt_9f81c3",
"trace_id": "trace_abcd1234",
"entity_id": "order_123",
"occurred_at": "2026-01-10T10:01:00Z",
"published_at": "2026-01-10T10:01:01Z",
"producer_service": "order-service",
"region": "ap-southeast-1",
"payload": {
"order_id": "order_123",
"user_id": "user_456",
"amount": 120,
"currency": "USD"
}
}Một event chuẩn không chỉ là payload. Nó mang theo:
- Business fact:
OrderCreatednghĩa là đơn hàng đã được tạo và commit - Versioned contract:
v1xác định ranh giới ổn định cho consumer - Metadata bắt buộc: phục vụ retry, tracing, replay, và fan-out multi-region
6. Versioning & Backward Compatibility
Trong fan-out:
- Producer không kiểm soát consumer
- Một breaking change ngầm = sự cố production dây chuyền
Backward-compatible change (thêm field optional)
{
"event_type": "OrderCreated.v1",
"payload": {
"order_id": "order_123",
"user_id": "user_456",
"amount": 120,
"currency": "USD",
"coupon_code": "NEWYEAR2026"
}
}- Thêm field mới, optional -> Consumer cũ không bị ảnh hưởng
Breaking change ⇒ version mới
{
"event_type": "OrderCreated.v2",
"payload": {
"order_id": "order_123",
"amount_cents": 12000,
"currency": "USD"
}
}v1vàv2chạy song song cho tới khi consumer migrate xong.
Consumer rule: ignore field lạ + idempotent
function handleOrderCreated(event) {
if (event.event_type !== "OrderCreated.v1") return;
const { order_id, amount, currency } = event.payload;
// idempotency by event_id
if (isProcessed(event.event_id)) return;
processOrder(order_id, amount, currency);
markProcessed(event.event_id);
}Nguyên tắc consumer:
- parse field cần, ignore field không biết
- chịu được duplicate / retry
=> Nhờ giữ contract nghiêm ngặt, nhiều team có thể subscribe, deploy và scale độc lập mà không cần sync mỗi sprint.
7. Schema Registry – Contract phải được enforce
Nói “event là product, contract là ranh giới sống còn” mà không có cơ chế enforce thì thường sẽ thành:
- producer publish “thoải mái”
- consumer tự đoán schema
- breaking change xuất hiện âm thầm
- sự cố production xảy ra theo kiểu “không ai biết bắt đầu từ đâu”
=> Vì fan-out có nhiều consumer và deploy không đồng bộ, enforce contract là thứ giữ hệ thống không vỡ khi scale team.
Giải pháp
- Dùng Schema Registry (AWS Glue Schema Registry / Confluent Schema Registry) để định nghĩa schema cho message dưới dạng schema-first (Avro / Protobuf / JSON)
- Producer validate schema trước khi publish
- CI/CD fail nếu schema thay đổi incompatible
- Consumer decode theo schema version rõ ràng
Tại sao Protobuf / Avro (thay vì JSON thuần)
- Payload nhỏ hơn JSON (thường 3–10x, tuỳ cấu trúc)
- Schema chặt chẽ, field có type rõ
- Versioning có quy tắc (add optional field là safe, breaking change phải bump version)
=> Ở scale lớn, payload nhỏ hơn không chỉ nhanh hơn — nó còn giảm chi phí network + storage + queue theo thời gian.
Minimum best-practice
Nếu hệ thống chưa đủ “mature” để có registry ngay, tối thiểu nên có:
- Schema file trong repo (OpenAPI/JSON Schema/Proto) + versioned
- Contract test trong CI:
- producer: validate payload theo schema
- consumer: test backward-compatibility (v1 vẫn parse được khi producer lên v1.1)
- Rule rõ ràng: add field = optional, remove/rename/type change = new version
8. Publish event đúng cách – Outbox Pattern
Vấn đề thực sự là gì?
Cách làm “nhìn có vẻ đúng”:
- Insert Order vào DB -> Publish event
Nhưng thật ra, hai bước này không atomic.
Chỉ cần:
- DB commit xong
- publish event bị timeout / network lỗi / process crash
=> Kết quả là data đã tồn tại nhưng event bị mất -> Downstream không bao giờ biết order đã được tạo -> hệ thống lệch trạng thái.
Trong event-driven, event là nguồn kích hoạt toàn bộ side-effect, mất event = mất analytics/notification/sync/cache warming…
Outbox giải quyết thế nào?
Outbox biến publish event thành một phần của transaction DB.
BEGIN;
INSERT INTO orders (...);
INSERT INTO outbox (
event_type,
payload,
created_at
) VALUES (
'OrderCreated.v1',
'{...}',
NOW()
);
COMMIT;- Order và event commit cùng lúc
- Hoặc cả hai thành công
- Hoặc cả hai rollback
=> Không có trạng thái “có data nhưng mất event”.
Vai trò của worker outbox
Worker riêng đảm nhiệm việc “đẩy event ra ngoài”:
- poll bảng outbox
- publish event lên SNS
- mark record
published
Nếu worker crash hoặc SNS lỗi -> record vẫn nằm trong outbox và được retry sau.
Outbox không làm event real-time hơn. Nó làm event đáng tin hơn.
=> Outbox Pattern đảm bảo: nếu data tồn tại, event nhất định sẽ được phát ra.
9. Consumer bắt buộc: Idempotent + Retry + DLQ
Trong event-driven architecture với SNS/SQS, message delivery gần như luôn là at-least-once:
- Message có thể được deliver nhiều lần
- Có thể đến trễ
- Có thể bị retry nhiều lần
=> Vì vậy consumer bắt buộc phải idempotent và chấp nhận duplicate một cách an toàn.
Pseudo-code (JavaScript)
async function handleMessage(msg) {
const { event_id, payload } = msg;
// 1) Idempotency check
// Nếu event đã xử lý -> ACK ngay (delete message)
if (await isProcessed(event_id)) {
return;
}
try {
// 2) Business logic
await process(payload);
// 3) Mark processed
await markProcessed(event_id);
// 4) Success -> ACK (delete message)
return;
} catch (err) {
// 5) Lỗi tạm thời (network, throttling, timeout, 5xx)
// THROW = KHÔNG ACK => message sẽ quay lại queue sau VisibilityTimeout
if (isTemporary(err)) {
throw err;
}
// 6) Lỗi vĩnh viễn (validation, business rule)
// Nếu muốn SQS tự đẩy sang DLQ theo redrive policy:
// THROW = KHÔNG ACK => message sẽ retry; vượt maxReceiveCount => move to DLQ
logPermanentError(err);
throw err;
}
}- Exactly-once là một mục tiêu hợp lệ trong một số bài toán nhất định. Thường đòi hỏi transactional messaging + state coordination chặt, tăng latency và tăng rủi ro vận hành.
=> Vì vậy, nhiều hệ thống production chọn chấp nhận duplicate. Kết hợp idempotency + retry + DLQ để xử lý an toàn và ổn định.
10. Bảo vệ consumer – tránh self-inflicted DDoS
Fan-out giúp scale rất tốt, nhưng nếu không kiểm soát retry, chính consumer sẽ trở thành thứ tấn công hệ thống downstream của mình.
Kịch bản chết người
- Database / downstream service bắt đầu chậm (latency tăng, chưa chết)
- Consumer xử lý timeout -> retry
- Autoscaling thấy queue còn nhiều -> scale thêm consumer
- Consumer retry đồng loạt
- DB từ chậm -> overload -> chết hẳn
=> Đây không phải DDoS từ bên ngoài, mà là self-inflicted DDoS do thiết kế retry sai.
Nguyên nhân gốc rễ
- Retry không delay, không jitter
- Retry đồng bộ (retry cùng nhịp)
- Không có cơ chế ngắt khi downstream đang unhealthy
- Autoscaling khuếch đại lỗi (error amplification)
Giải pháp
Circuit Breaker – ngắt khi downstream đang chết
Circuit Breaker bảo vệ consumer bằng cách:
- Khi error rate / timeout vượt ngưỡng -> OPEN
- Consumer fail fast, không tiếp tục bắn request xuống DB
- Cho downstream thời gian hồi phục
- Sau cooldown -> HALF-OPEN -> test nhẹ -> nếu ổn thì CLOSE lại
=> Mục tiêu: giảm áp lực, không phải cố xử lý cho bằng được.
Exponential Backoff + Jitter
Retry không được đồng loạt, giãn dần + random để tránh retry storm
1s +random(0..1s)
2s +random(0..2s)
4s +random(0..4s)
8s +random(0..8s)- Exponential: giãn dần khoảng cách retry
- Jitter (random): tránh hàng trăm consumer retry cùng thời điểm
=> Không jitter = retry storm.
Nguyên tắc
- Retry để hồi phục, không phải để giết hệ thống
- Nếu downstream đang yếu -> chậm lại
- Nếu downstream đang chết -> ngắt hẳn
- Autoscaling + retry phải được thiết kế cùng nhau, không được tách rời
=> Fan-out chỉ thực sự chịu lỗi tốt khi consumer biết tự kiềm chế.
11. Poison Pill & MaxReceiveCount – cơ chế “ngắt” bắt buộc
Poison pill là gì?
Một message không bao giờ xử lý được, ví dụ:
- payload thiếu field bắt buộc, data corrupted, version schema không support
Luồng chết người:
Receive -> Fail -> ReturnQueue -> Receive -> Fail -> ReturnQueue -> Receive -> ...=> Queue bị nghẽn bởi 1 message hỏng, các message tốt phía sau bị ăn bớt tài nguyên
Giải pháp: maxReceiveCount
Cấu hình Redrive Policy cho SQS:
- Message fail quá N lần -> SQS tự động đẩy sang DLQ -> Queue chính được giải phóng
- DLQ ≠ “chỗ vứt rác”, DLQ = nguồn dữ liệu để fix bug / replay có kiểm soát
- Monitor: DLQ message count, DLQ arrival rate
=> Không có maxReceiveCount = leak tài nguyên vô hạn
12. Visibility Timeout – thông số hay bị bỏ quên nhưng phá production
Trong SQS, mỗi message sau khi được consumer nhận sẽ biến mất tạm thời trong khoảng Visibility Timeout.
Nếu:
Visibility Timeout > Thời gian xử lý thực tếthì:
- Consumer A đang xử lý -> timeout hết -> message xuất hiện lại trong queue
- Consumer B nhận lại -> A và B xử lý cùng message
=> Duplicate amplify, DB load tăng, retry storm, sự cố dây chuyền.
Giải pháp:
- VisibilityTimeout ≥ P95/P99 processing time × 3 (thậm chí ×6)
- Và nếu xử lý lâu: consumer nên có cơ chế extend visibility.
13. Tránh shared DB write – anti-pattern nguy hiểm
Trong fan-out, nhiều consumer xử lý cùng một event gần như đồng thời và event có thể bị duplicate. Nếu tất cả cùng ghi vào một DB/table dùng chung, hệ thống sẽ nhanh chóng gặp vấn đề:
- Race condition / lost update do ghi đè không kiểm soát
- Deadlock / lock contention khi traffic tăng
- Retry storm khiến DB bị choke vì write burst
- Ownership mơ hồ, rất khó trace và debug khi data sai
Best practice
- Mỗi consumer own data store của mình, DB riêng hoặc tối thiểu là schema/table riêng
- Không service nào được ghi trực tiếp DB của service khác
Lợi ích
- Blast radius nhỏ: lỗi ở consumer nào, ảnh hưởng DB của consumer đó
- Retry an toàn, không kéo sập DB chung
- Ownership rõ ràng, audit và debug dễ
- Scale độc lập, thêm consumer không đụng data hiện tại
14. Message Filtering – fan-out nhưng không spam
Vấn đề thực tế
Trong fan-out:
- 1 SNS Topic có thể publish hàng trăm nghìn -> triệu event/giây
- Nhưng mỗi consumer chỉ quan tâm một phần nhỏ, nếu nhận 100% rồi discard -> đốt tiền.
Ví dụ:
- Topic:
OrderCreated - Consumer A chỉ cần
international - Consumer B chỉ cần
domestic
Nếu tất cả consumer nhận 100% message rồi tự discard:
- SNS vẫn fan-out full
- SQS/Lambda/ECS vẫn nhận & poll
- Deserialize + network + compute vẫn tốn tiền
=> Chi phí tăng tuyến tính theo traffic, dù business value = 0
Giải pháp: SNS Subscription Filter
SNS cho phép filter ngay tại tầng fan-out (SNS), trước khi message được đẩy xuống consumer. Điểm quan trọng:
- Filter dựa trên Message Attributes
- Không filter body
Producer publish event (kèm Message Attributes)
{
"Message": "{...binary or json payload...}",
"MessageAttributes": {
"order_type": {
"DataType": "String",
"StringValue": "international"
},
"region": {
"DataType": "String",
"StringValue": "EU"
}
}
}=> Payload không đổi cho từng consumer, routing nằm hoàn toàn ở attributes
Ví dụ tạo Subscription Filter với CloudFormation
OrderInternationalSubscription:
Type: AWS::SNS::Subscription
Properties:
TopicArn: !Ref OrderCreatedTopic
Protocol: sqs
Endpoint: !GetAtt ShippingQueue.Arn
FilterPolicy:
order_type:
- international=> Chỉ message có order_type=international mới được gửi xuống queue ShippingQueue, consumer chỉ nhận đúng event cần thiết
15. Large Payload – Claim Check Pattern
SNS/SQS giới hạn ~256KB.
Giải pháp: Claim Check Pattern
- Upload payload lớn lên S3
- Message chỉ chứa reference
{ "event_type": "OrderCreated.v1", "payload_ref": "s3://bucket/events/evt_123.json" }
=> Message nhẹ, rẻ, scale tốt.
16. Backpressure & Autoscaling – vì sao hệ thống chịu được spike
- SNS được thiết kế để fan-out & push nhanh, buffer ngắn
- SQS là durable queue, chịu được traffic spike, consumer chậm, scale không kịp
=> Backpressure thực sự nằm ở SQS, không phải SNS.
Scale consumer theo queue depth, không theo CPU
CPU thấp không có nghĩa là khỏe trong event system:
- Consumer không xử lý liên tục như web server, consumer có thể idle vì đang chờ message
- Queue có thể đang chất đống, event đến muộn -> Business latency tăng
Queue depth mới là “áp lực thật”
ApproximateNumberOfMessagesVisible cho biết bao nhiêu message đang chờ được xử lý
Ví dụ về cấu hình autoscaling:
Metric:ApproximateNumberOfMessagesVisible
TargetValue:100Nghĩa là:
- Mỗi consumer chịu trách nhiệm ~100 message
- Nếu queue có:
- 1,000 messages -> scale lên ~10 consumer
- 100 messages -> giữ ~1 consumer
=> Autoscaling theo nhu cầu thực, không theo tài nguyên máy.
17. Observability – trace event, không chỉ service
Trong event-driven, thứ cần theo dõi không phải service, mà là event. Service chỉ là chặng đi qua; event đi xuyên toàn hệ thống.
Vì sao chỉ trace service là chưa đủ?
Service-level monitoring không cho biết:
- Event đang ở đâu, kẹt ở queue nào
- Đã retry bao nhiêu lần, mất bao lâu từ publish -> xử lý xong
=> Service “xanh” nhưng business vẫn không chạy.
Trace event cần những gì?
Mỗi event phải có định danh xuyên suốt:
event_id– định danh duy nhấttrace_id– định danh toàn flow
Hai giá trị này phải có trong message, log, metric, trace.
Debug = search theo event_id là thấy toàn bộ lifecycle.
Các metric đi kèm event để hỗ trợ debug có thể là: Publish rate, Queue depth / message age, Retry & DLQ rate, End-to-end latency theo event
Combo tooling phổ biến (log + metric + trace)
- AWS-native: CloudWatch Logs + Metrics + X-Ray
- Cloud-agnostic: Loki/ELK + Prometheus + Grafana + OpenTelemetry (Tempo/Jaeger)
18. Fan-out Depth & Cross-Account – giới hạn kỹ thuật + tổ chức
Ở quy mô lớn, fan-out không chỉ là kiến trúc, mà là bài toán kết hợp:
- AWS quota (SNS subscriptions / topic)
- cross-account (mỗi team/domain một AWS Account), governance & ownership theo team
Giới hạn kỹ thuật (AWS quota)
- SNS có quota subscription/topic
- Theoretical cao nhưng default account quota có thể thấp
- Scale đột ngột không planning quota -> deploy fail bất ngờ
=> Scale fan-out phải xin quota trước, không xử lý sau.
Cross-Account fan-out
Trong quy mô lớn:
- Producer không sở hữu consumer
- Consumer tự quản SQS/Lambda/ECS
- Khác account -> bắt buộc cross-account fan-out
Vấn đề cốt lõi
SNS -> SQS cross-account không tự hoạt động, cần đúng policy:
- SQS Queue Policy (bắt buộc): cho phép SNS Topic ARN cụ thể gọi
SQS:SendMessage - SNS Topic Policy (khi cần): cho phép account khác tạo subscription
- IAM role / trust: quyền tạo subscription & quản lý resource
=> Sai 1 condition trong SQS policy -> subscription vẫn enabled -> publish success -> queue không nhận message.
Kết luận
Fan-out architecture không phải là một “kỹ thuật gửi message cho nhiều nơi”, mà là một quyết định kiến trúc nhằm giúp hệ thống chịu lỗi tốt hơn, scale tuyến tính hơn, và cho phép tổ chức phát triển độc lập theo team. Nhưng khi bước vào high traffic, multi-team, multi-account, những rủi ro bắt đầu lộ diện: coupling vô hình, retry dây chuyền, chi phí tăng phi tuyến, và debug không điểm bắt đầu. Fan-out, nếu được thiết kế đúng, chính là cách cắt đứt các ràng buộc đó.
Qua toàn bộ bài viết, có thể rút gọn thành vài nguyên tắc cốt lõi:
- Fan-out không thay thế Saga: Saga giữ critical path đúng và nhất quán; fan-out xử lý phần còn lại một cách async và chịu lỗi.
- Event là product, không phải implementation detail: contract phải versioned, backward-compatible và được enforce.
- Reliability nằm ở consumer: idempotency, retry, DLQ, visibility timeout và cơ chế bảo vệ downstream là bắt buộc, không phải “nice-to-have”.
- Isolation là nền tảng để scale: mỗi consumer có queue, retry, autoscaling và data ownership riêng, tránh lan lỗi.
- Chi phí và độ ổn định phụ thuộc vào thiết kế fan-out: filtering, backpressure, autoscaling theo queue depth quyết định hệ thống sống khỏe hay tự DDoS chính mình khi spike.
- Observability phải xoay quanh event: trace theo event lifecycle để phát hiện sớm retry storm, backlog và amplification, không chỉ nhìn service “xanh hay đỏ”.
Bài viết đến đây cũng đã rất dài, cảm ơn anh chị và các bạn đã dành thời gian đọc đến cuối. Nội dung trong bài là những gì em tìm hiểu, nghiên cứu về system design và đúc kết lại thông qua trải nghiệm thực tế khi làm việc và học hỏi, không nhằm dạy hay áp đặt một cách làm “đúng” cho bất kỳ ai. Hy vọng những chia sẻ này mang lại thêm một góc nhìn để mọi người tham khảo, đối chiếu với bối cảnh của riêng mình trong quá trình học tập và làm việc. Chúc anh chị và các bạn luôn giữ được tinh thần tốt, làm việc hiệu quả và tiếp tục tiến xa trên con đường mình theo đuổi. Cảm ơn mọi người rất nhiều.