Nay lại có dịp chia sẻ về giải quyết bài toán kinh điển về No space left on device, cái này chắc anh em làm hệ thống ai cũng từng gặp và thông báo cũng đã rất rõ ràng rồi nhưng issue thì vô vàn và không phải lúc nào nguyên nhân cũng sẵn ra đó để mà chỉ cần xóa log, clear docker,…
Hệ thống bên mình có phần vận hành mail server (Postfix/Dovecot) và các ứng dụng cache file-based (như PHP session storage cũ), việc giám sát dung lượng disk là quy trình bắt buộc. Mình đang quản lý một cluster Linux sử dụng Filesystem EXT4, được mount vào /var để chứa data (nói về cách mount cũng vô vàn luôn).
Server này chịu tải ghi liên tục với đặc thù là sinh ra hàng triệu file kích thước rất nhỏ khoảng vài KB. Hệ thống Monitoring bên mình xài rất quen thuộc Prometheus/Grafana vẫn báo Disk Usage ở mức an toàn tầm 60%. Tuy nhiên, application đột ngột crash hàng loạt và không thể ghi thêm dữ liệu mới.

Mọi thao tác ghi file như touch, cp, hay log rotation đều không được tại tầng Kernel dù disk vẫn còn hàng trăm GB trống. Đây cũng có thể là usecase giúp được anh em.
Hiện tượng ghi nhận
Khi mình SSH vào server để kiểm tra, triệu chứng đầu tiên là không thể dùng Tab completion cho một số lệnh vì shell không thể tạo temporary file.
Application logs thì toàn lỗi: write error: No space left on device
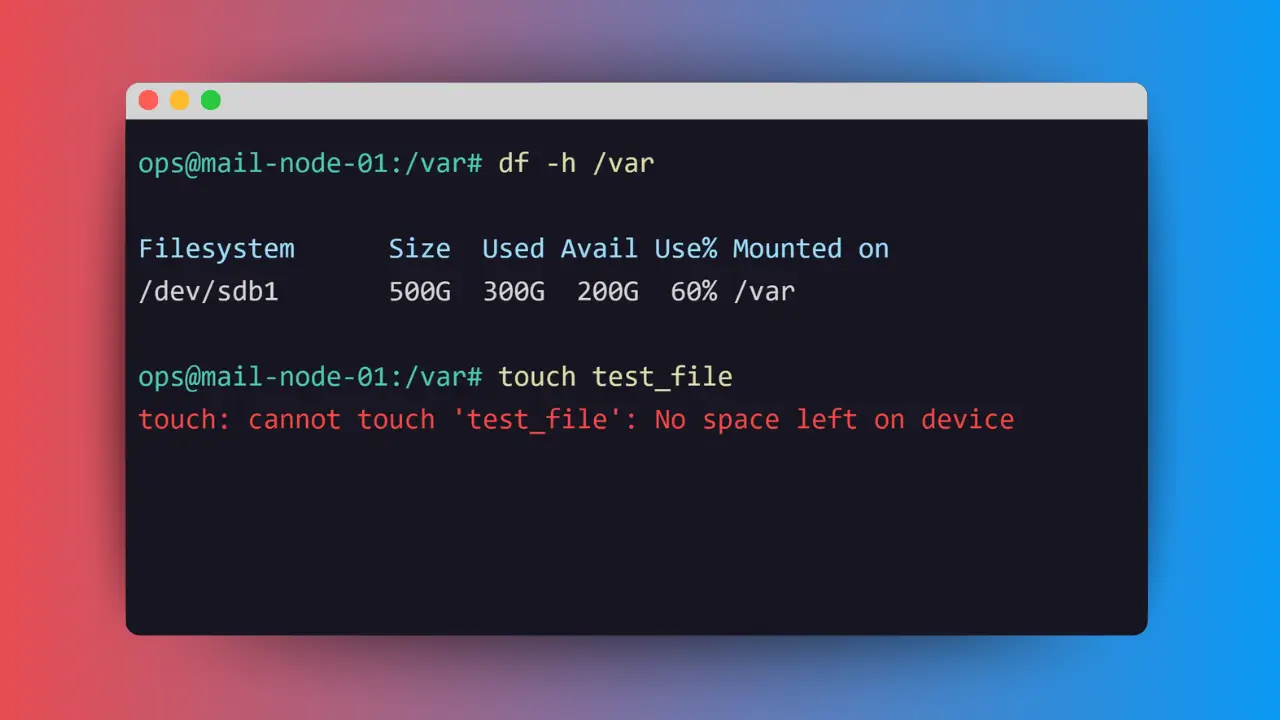
Mình kiểm tra dung lượng đĩa nhanh df -h /var
Kết quả:
Filesystem Size Used Avail Use% Mounted on
/dev/sdb1 500G 300G 200G 60% /varRõ ràng Disk space vẫn còn dư 200GB. Nhưng khi thử tạo một file rỗng: touch /var/test_file
Hệ điều hành trả về:
touch: cannot touch '/var/test_file': No space left on deviceĐây là trạng thái ENOSPC từ Syscall trả về, nhưng nguyên nhân không nằm ở Data Block.
Dấu hiệu
Ban đầu, cũng nghi ngờ các Process đang giữ file đã bị xóa, khiến dung lượng không được giải phóng. Đây là tình huống thường gặp khi log rotation không gửi signal chính xác cho application.
Mình kiểm tra bằng lsof: lsof | grep deleted
Kết quả trả về vài file log cũ, nhưng tổng dung lượng bị held chỉ vài trăm MB, không đủ để giải thích việc mất 200GB. Buốt óc P1 :)))
Tiếp theo, mình nghi ngờ Filesystem corruption khiến Superblock báo sai thông tin. Tuy nhiên, dmesg không hiển thị bất kỳ lỗi I/O error hay filesystem error nào từ Kernel. Buốt óc P2 :)))
Rồi sau thời gian mày mò (cả đi hỏi) và vấn đề thực sự nằm ở kiến trúc của Filesystem mà các công cụ giám sát thường bỏ qua.
Nguyên nhân và khắc phục
Nguyên nhân
Ở đây là sự là inode exhaustion trên filesystem.
Trong kiến trúc EXT4 và nhiều Unix-like filesystems, dữ liệu được lưu ở hai nơi:
- Data Blocks: Chứa nội dung thực sự của file.
- Inodes: Là cấu trúc dữ liệu metadata chứa thông tin về file gồm permission, owner, timestamp, vị trí các blocks.
Mỗi file sinh ra bắt buộc phải tiêu tốn ít nhất 1 Inode. Khi format phân vùng EXT4, số lượng Inode tối đa được cố định ngay từ đầu dựa trên cấu hình bytes-per-inode và không thể thay đổi trừ khi format lại hoặc resize filesystem với cờ đặc biệt, nhưng rất rủi ro.
Mình kiểm tra bảng Inode bằng lệnh: df -i /var
Kết quả xác nhận giả thuyết:
Filesystem Inodes IUsed IFree IUse% Mounted on
/dev/sdb1 3.2M 3.2M 0 100% /varIUse% là 100%. Dù Data Blocks còn trống rất nhiều, nhưng Filesystem đã hết slot để định danh file mới. Kernel từ chối cấp phát Inode mới, trả về lỗi No space left on device.
Vấn đề này xảy ra do workload sinh ra quá nhiều file nhỏ. Mỗi file chỉ chiếm 4KB block nhưng lại mất 1 Inode. Với cấu hình mặc định, EXT4 thường dự trù 1 Inode cho mỗi 16KB dữ liệu. Nếu kích thước trung bình file của bạn nhỏ hơn con số này, bạn sẽ hết Inode trước khi hết dung lượng đĩa.
Khắc phục:
Ngắn hạn: Mình tìm và xóa các file nhỏ không cần thiết để giải phóng Inode. Việc dùng ls -R hay find trên thư mục chứa hàng triệu file sẽ làm treo I/O vì dentry cache quá lớn.
Cách tối ưu là dùng rsync để xóa hoặc xóa dựa trên inode directory entry mà không cần sort lại danh sách file: find /var/lib/php/sessions -type f -mtime +7 -delete
Thêm cách nữa cho mọi người tham khảo là nếu thư mục quá lớn thì có thể move thư mục đó sang một partition khác (nếu có) rồi format lại thư mục cũ (nhưng cách này gây downtime).
Sau khi xóa khoảng 500.000 files session cũ, Inode usage giảm xuống 85%, hệ thống là ngon luôn.
Kết luận
Từ sự cố này, mình thấy một vài thứ về Infrastructure:
Thứ nhất, Monitoring phải bao gồm cả metric node_filesystem_files_free hoặc track Inode Utilization. Đừng bao giờ chỉ nhìn vào disk_free_bytes.
Thứ hai, hiểu rõ Workload trước khi chọn Filesystem. Nếu ứng dụng sinh ra rất nhiều file nhỏ như cache server, mail queue, EXT4 với default option không phải là lựa chọn tốt.
- Nếu vẫn dùng EXT4: Phải format với option
-i(ví dụ-i 4096) để tăng số lượng Inode tối đa lúcmkfs. - Cân nhắc chuyển sang XFS: XFS quản lý dynamic inode, nó có thể cấp phát thêm Inode block khi cần thiết miễn là còn disk space, giúp tránh tình trạng hard limit như EXT4.
Thứ ba, thiết kế ứng dụng nên tránh lưu trữ millions of files trong một cấu trúc flat directory. Việc lookup file trong một directory quá lớn cũng gây áp lực lên Virtual File System cache và làm chậm hệ thống. Nên chia nhỏ data thành nhiều sub-directory hoặc chuyển sang dùng Object Storage/Database cho các dữ liệu dạng này là ngon luôn.