
Đi làm cũng hay docs, viết bài chia sẻ cũng thành thói quen vừa giúp được anh em cộng đồng vừa có tí niềm vui khi thấy anh em vào còm men khen hữu ích :))

Ngoài các kiến thức, kinh nghiệm thực tế cá nhân ra tôi cũng hay đi lọ mọ đọc các tech blog. Như ở bài LinkedIn đã vận hành 1 Exabyte dữ liệu trên HDFS như thế nào? mọi người đã biết cách LinkedIn scale cái hệ thống HDFS lên tới 1 Exabyte dữ liệu. Hôm trước tôi cũng có mò tiếp thấy được phần chia sẻ khác và tôi có note lại nay rảnh mới ngồi ngâm cứu và viết lại nội dung cũng rất hay tiếp theo của Linkedin về hành trình họ đập đi xây lại cả một hệ thống phân tích dữ liệu của họ. Từ hệ thống cồng kềnh của nền tảng cũ, họ đã chuyển sang một new tech với big data open-sources, mọi người có thể tìm hiểu thử để thêm góc nhìn và học hỏi được giá trị gì không nhé.
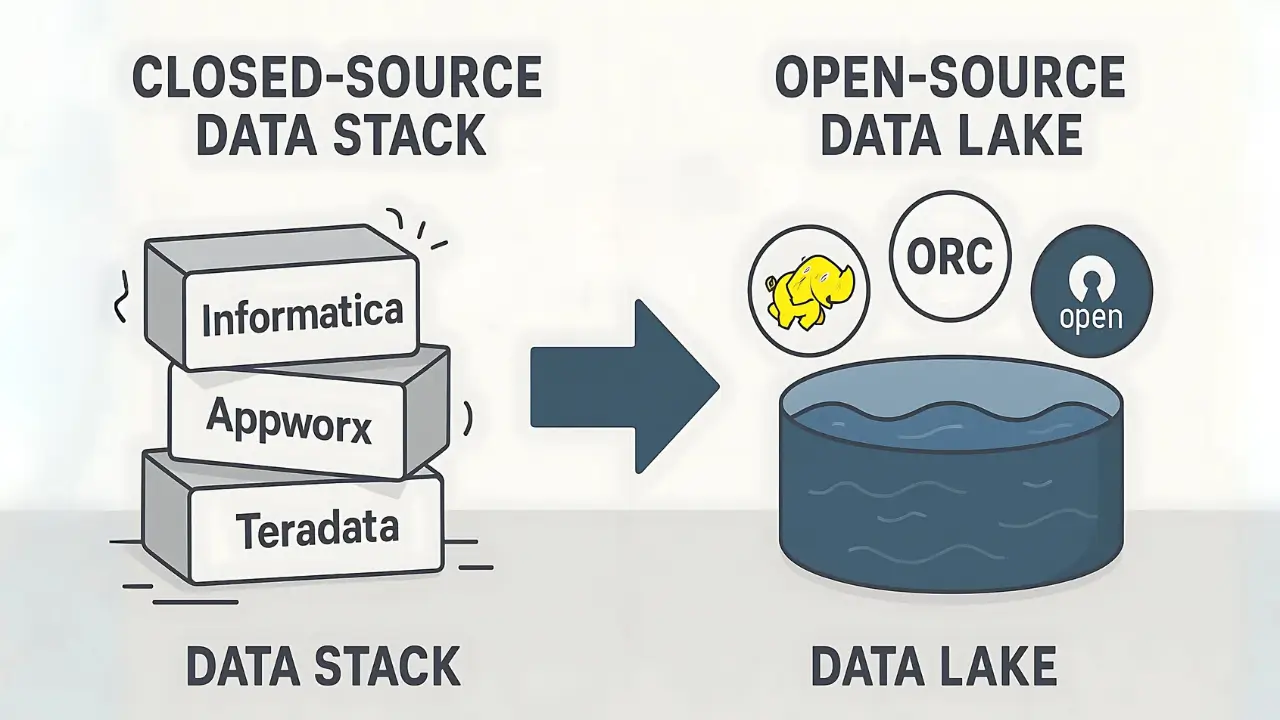
Gánh nặng hệ thống cũ của LinkedIn
Hồi đầu những năm 2010, LinkedIn bùng nổ phát triển. Để kịp đáp ứng tốc độ tăng trưởng chóng mặt, họ quyết định chơi nhanh thắng nhanh bằng cách dùng các giải pháp phần mềm độc quyền của bên thứ ba. Nhờ vậy, họ có thể triển khai hệ thống phân tích ngay lập tức mà không cần tốn thời gian tự build từ đầu.
Cụ thể, LinkedIn sử dụng Informatica và Appworx cho các quy trình ETL (Extract, Transfer, Load) để đưa dữ liệu vào Data Warehouse rồi đổ hết vào kho dữ liệu Teradata. À, cho ai chưa rõ thì ETL nôm na là quá trình gom dữ liệu từ nhiều nơi, xử lý và đẩy hết vào một chỗ để tiện cho việc phân tích.
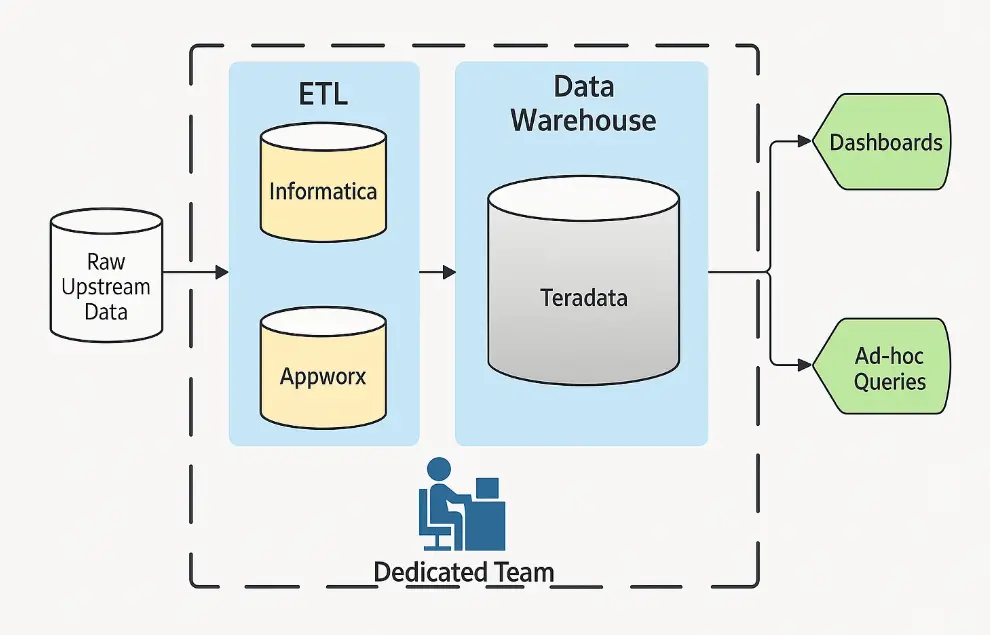
Hệ thống này đã phục vụ ngon lành trong 6 năm. Nhưng cái gì cũng có cái giá của nó, và đây là những điểm yếu của nó:
- Hạn chế khả năng phát triển: Vì đây là hệ thống đóng (closed-source), họ bị giới hạn trong việc đổi mới và sáng tạo hay tích hợp với các hệ thống nội bộ hoặc open source khác. Muốn làm gì cũng khó.
- Khó scale: License của Informatica/Appworx có hạn, khiến việc phát triển các data pipeline chỉ gới hạn trong một team nhỏ. Điều này đã cản trở sự phát triển của LinkedIn.
Để giải quyết các vấn đề trên, các kỹ sư LinkedIn bắt đầu xây song song Data lake mới trên nền tảng Hadoop. Tuy nhiên, do không có một lộ trình chuyển đổi rõ ràng, họ rơi vào một cái bẫy cực kỳ oái oăm: phải maintain cả hai hệ thống cùng một lúc.
Dữ liệu cứ thế được copy qua lại giữa hai stack, dẫn đến chi phí và độ phức tạp tăng gấp đôi.
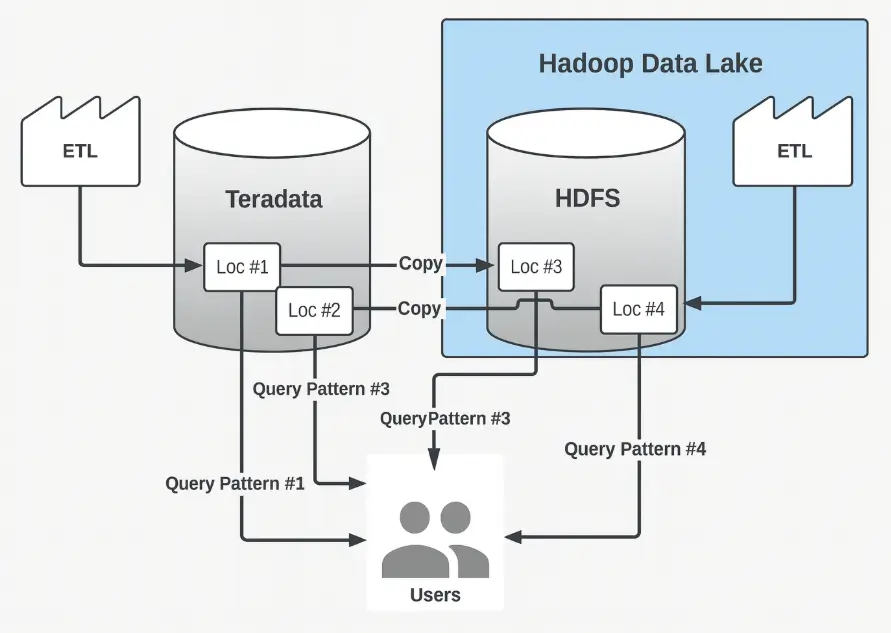
Data Migration
Để giải quyết tình trạng này, các kỹ sư đã quyết định migration toàn bộ dataset sang hệ thống analytics mới dựa trên Hadoop.
Bước 1: Xác định Data Lineage
Bước đầu tiên và quan trọng nhất là xác định Data Lineage của LinkedIn. Hiểu đơn giản, đây là quá trình theo dõi hành trình của dữ liệu từ lúc được tạo ra cho đến khi được sử dụng, ghi lại tất cả những biến đổi mà nó đã trải qua.
Nhờ có Data Lineage, các kỹ sư có thể:
- Lập kế hoạch migration các dataset một cách hợp lý.
- Xác định các dataset không còn được sử dụng để loại bỏ, giảm tải công việc.
- Theo dõi mức độ sử dụng giữa hệ thống mới và cũ.
Bước 2: Tái cấu trúc và tối ưu hóa
Dựa trên thông tin từ Data Lineage, họ lên kế hoạch tái cấu trúc lại mô hình dữ liệu. Một quyết định táo bạo là gộp 1424 dataset cũ lại thành 450 dataset. Nhờ vậy, họ đã giảm được được khoảng 70% migration workload.
Trong quá trình này, họ cũng chuyển đổi các dataset từ workload OLTP sang mô hình phù hợp hơn cho phân tích nghiệp vụ.
Một phát hiện thú vị khác là hiệu suất đọc của định dạng file Avro rất tệ. Họ đã nhanh chóng chuyển sang dùng ORC. Kết quả: tốc độ đọc tăng từ 10 đến 1000 lần, trong khi tỷ lệ nén cũng cải thiện từ 25% đến 50%. Quá đỉnh:)
Bước 3: Tự động hóa việc loại bỏ hệ thống cũ
Việc ngừng hỗ trợ hơn 1400 dataset một cách thủ công vừa tốn thời gian vừa dễ sai sót. Thế là các kỹ sư xây luôn một hệ thống tự động để xử lý.
Dịch vụ này sẽ tự động tìm các dataset có thể xóa (không có dependency và có mức độ sử dụng thấp), gửi email thông báo cho người dùng. Sau một thời gian chờ, nó sẽ báo cho đội SRE để khóa, lưu trữ và xóa hẳn dataset đó khỏi hệ thống cũ.
Thành quả: Hệ thống mới và những cải tiến vượt trội
Thiết kế mới đã giải quyết triệt để mọi vấn đề của hệ thống cũ:
- Dân chủ hóa dữ liệu (Democratization of data): LinkedIn có thể tự do phát triển và sử dụng dữ liệu trên nền tảng Hadoop, thay vì phải phụ thuộc vào một nhóm trung tâm như trước.
- Dân chủ hóa phát triển công nghệ: Mọi thành phần trong hệ thống đều có thể được cải tiến nhờ các dự án mã nguồn mở hoặc tự xây dựng, không còn bị bó hẹp bởi các giải pháp độc quyền.
- Thống nhất công nghệ: Việc loại bỏ hệ thống cũ đã giúp đơn giản hóa kiến trúc và tăng hiệu quả một cách đáng kể.
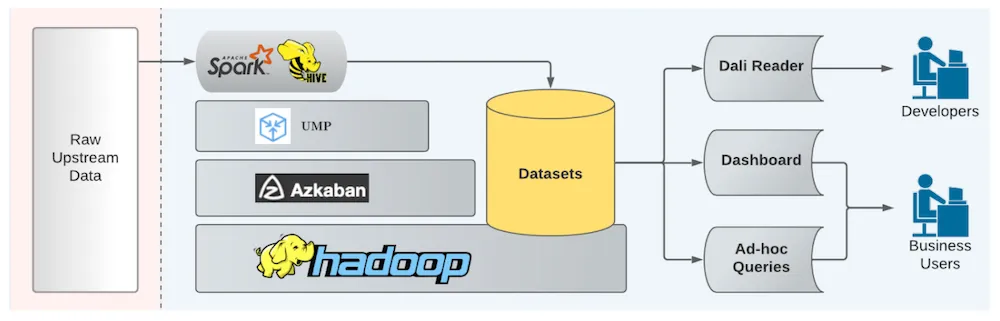
Các thành phần chính của hệ thống mới bao gồm:
- Unified Metrics Pipeline: Nền tảng thống nhất cho developer xây dựng các data pipeline ETL.
- Azkaban: Công cụ quản lý các job trên Hadoop.
- Dataset Readers: Dữ liệu được lưu trữ trên HDFS và và có thể được đọc theo nhiều cách khác nhau:
- Thông qua DALI, một API được phát triển để cho phép các kỹ sư LinkedIn đọc dữ liệu mà không cần quan tâm đến phương tiện lưu trữ, đường dẫn hay định dạng của nó.
- Thông qua các Dashboards và các ad-hoc queries cho phân tích nghiệp vụ.
Nhìn chung, cuộc chuyển đổi này của LinkedIn là một bài học đắt giá về việc từ bỏ các giải pháp ngắn hạn, tập trung vào xây dựng một kiến trúc linh hoạt và có khả năng mở rộng trong tương lai

















