Chào các bác, nay tôi muốn chia sẻ lại một sự cố khá khoai mà tôi từng gặp phải, thật ra là lục lại docs xem xét vài thứ để nhảy việc mà thấy rất hữu ích nên chia sẻ có thể sẽ giúp được anh em khi gặp bài toán như vậy. Vấn đề này nghe thì rất cơ bản nhưng lại có thể oánh sập cả Control-plane của một Cluster Production nếu chúng ta không để ý kỹ các limit ngầm của Kubernetes.
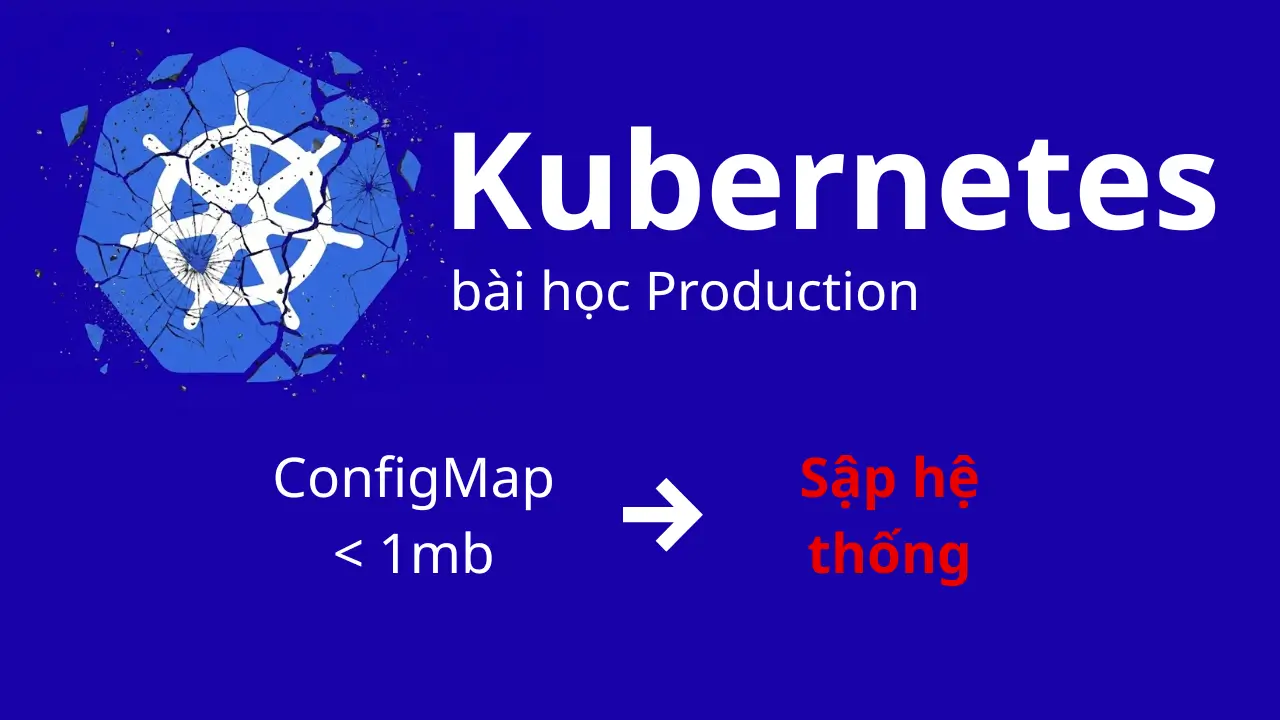
Đó là câu chuyện về việc lạm dụng ConfigMap để chứa dữ liệu lớn và cái giá phải trả của latency thật sự là làm ở công ty hiện tại lớn một chút mới có cơ hội tiếp cận bài toán kiểu này : D.
Hiện trạng lúc đó
Hệ thống thì Kubernetes Cluster khoảng 25 Nodes trên môi trường Cloud, có thể anh em thấy to vì khi tôi có trà đá với mấy anh em trong ngành thấy thậm trí production chạy Cluster 3 6 node vẫn thấy ổn, nên tóm lại cũng chỉ là con số thôi còn tùy thuộc vào cấu hình mỗi con bao nhiêu nữa.
Kiến trúc thì chủ yếu là Microservices, nhưng có một service Legacy (tôi tạm gọi là Service-Legacy) cần load một file cấu hình routing rất phức tạp định dạng XML.

Team Dev quyết định không build cứng file XML này vào Container image vì họ muốn thay đổi routing nhanh chóng mà không cần chạy lại pipeline build image. Giải pháp được chọn là đưa toàn bộ nội dung file XML này vào một ConfigMap. File này nặng khoảng 950KB (gần chạm ngưỡng giới hạn 1MB mặc định của etcd).
Quy trình deploy vẫn diễn ra qua GitOps. Mọi thứ có vẻ bình thường cho đến khi họ update file config này lần thứ hai trong giờ cao điểm.
Triệu chứng nhận được
Ngay khi pipeline GitOps apply thay đổi lên Cluster, hệ thống monitoring bắt đầu báo động đỏ:
- API Server Latency Spike: P99 latency của các request tới API Server tăng vọt từ 50ms lên tới 2-3s, thậm chí timeout.
- kubectl Sluggish: Các lệnh
kubectl get podsđơn giản cũng bị treo hoặc trả về lỗi timeout. - Node Flapping: Một số Node bắt đầu chuyển trạng thái từ
ReadysangNotReadyrồi lạiReady. - etcd Alerts: Metric
etcd_disk_wal_fsync_duration_secondstăng cao bất thường, cảnh báo etcd đang gặp vấn đề về Disk write latency.
Điều đáng sợ nhất là không chỉ Service-Legacy bị ảnh hưởng, mà toàn bộ hoạt động quản trị trên Cluster gần như không thể vận hành.
Hướng điều tra
Ban đầu, tôi và các bác trong team đã đi sai hướng vì các triệu chứng quá nhiễu:
- Nghi vấn 1: Network Issue. Thấy Node bị
NotReady, tôi nghĩ ngay đến vấn đề Network partition hoặc CNI plugin bị lỗi khiến Kubelet không thể gửi heartbeat về API Server. Chúng tôi kiểm tra VPC flow logs và Ping giữa các node nhưng mạng vẫn ổn định. - Nghi vấn 2: Resource Exhaustion trên Control-plane. CPU của các node chạy Master tăng vọt. Tôi nghĩ rằng traffic user tăng đột biến làm quá tải API Server. Tôi đã thử scale up Master node lên cấu hình cao hơn nhưng tình hình không cải thiện bao nhiêu.
- Nghi vấn 3: etcd Disk IOPS. Metric báo fsync chậm, tôi nghi ngờ Disk của etcd bị hỏng hoặc chạm ngưỡng IOPS. Tuy nhiên, check kỹ thì throughput disk không cao, chỉ có Latency là cao.
Cũng mất gần 30 phút loay hoay với hạ tầng mạng và VM specs mà không tìm ra nguyên nhân.
Root cause và Phương án xử lý
Sau khi soi kỹ logs của API Server, tôi phát hiện ra thủ phạm chính là cái ConfigMap 950KB kia.
Root Cause:
- etcd không được thiết kế để lưu trữ các object lớn. Khi một object gần 1MB được ghi vào, nó chiếm dụng băng thông xử lý của etcd và làm chậm quá trình replication giữa các node của etcd cluster.
- Vấn đề nghiêm trọng hơn nằm ở cơ chế LIST/WATCH của Kubernetes. File
routes.xmlnày được mount vào Pod. Khi ConfigMap thay đổi, API Server phải đẩy bản cập nhật 1MB này tới tất cả các Watchers. - Do
Service-Legacychạy khá nhiều Replicas rải rác trên nhiều Node, việc update tạo ra một lượng traffic burst đột ngột từ API Server đi ra. - Việc xử lý payload lớn khiến API Server bị nghẽn CPU do serialization và deserialization JSON, dẫn đến xử lý các request quan trọng khác bị chậm trễ => Node bị đánh dấu
NotReady=> kích hoạt Eviction => tạo thêm load => chết chùm.
Phương án xử lý:
- Ngắn hạn: Rollback ngay ConfigMap về version cũ hoặc xóa bớt nội dung để giảm size.
- Dài hạn:
- Chuyển file cấu hình lớn ra khỏi ConfigMap, build thẳng vào Container image.
- Nếu cần dynamic update, dùng Init container để download file từ Object Storage như S3.
- Thiết lập Resource Quota cho Namespace để giới hạn số lượng và kích thước ConfigMap.
Bài học kinh nghiệm
- etcd is for Coordination, not Storage: Không coi etcd là database thông thường. Object nên giữ dưới 100KB.
- Beware of the Watchers: Chi phí object không chỉ là storage mà là network nhân với số Watchers.
- Monitor Control-plane metrics: Cần alert kỹ cho etcd và API Server latency.
- Immutable Infrastructure: Config lớn nên được treat như code: Build, Test và Deploy qua Image.
Đây thực sự là một case study tôi note lại mà rất muốn lan tỏa đến các bác. Cũng vì gần đây thấy có sự kiện Observability with Datadog của DevOps VietNam tổ chức cùng Datadog thấy có chuyên gia từng làm SRE tại J.P. Morgan chia sẻ nên tôi cũng hóng quá và nảy ra ý tưởng chia sẻ, có khi hôm đấy lại +1 kiến thức để áp dụng và sau lại có cái share với anh em 😀