Làm thế nào để migrate một hệ thống cơ sở dữ liệu khổng lồ mà không gây gián đoạn cho người dùng? Đây là câu hỏi mà đội ngũ kỹ sư tại Atlassian phải đối mặt và họ đã giải quyết thách thức này như thế nào?
Tại Atlassian, việc di chuyển cơ sở dữ liệu ở quy mô lớn là một phần của công việc vận hành thường xuyên nhằm rebalancing trên toàn bộ hệ thống database của Jira. Trung bình, họ dịch chuyển khoảng một nghìn database mỗi ngày mà gần như không gây ra bất kỳ gián đoạn nào cho khách hàng. Tuy nhiên, gần đây, họ phải đối mặt với một thách thức ở một cấp độ hoàn toàn mới.
Làm thế nào để dịch chuyển vài triệu cơ sở dữ liệu mà giảm tối đa gián đoạn cho người dùng?
Bối cảnh hệ thống
Jira sử dụng Postgres làm kho lưu trữ chính. Mọi thứ từ issue, project, workflow cho đến custom field đều được lưu trữ trong cơ sở dữ liệu với kiến trúc một database cho mỗi tenant Jira. Với hàng triệu tenant, điều này đồng nghĩa với việc Atlassian đang vận hành hàng triệu database.
Kiến trúc “một database mỗi tenant” không phổ biến, nhưng Atlassian đã lựa chọn nó để tối đa hóa isolation, scalability, và Operational Control ở quy mô khổng lồ. Kiến trúc này giúp đảm bảo dữ liệu của một tenant không thể bị truy cập vô tình hay cố ý bởi một tenant khác, đồng thời cho phép mở rộng hệ thống theo chiều ngang, cân bằng tải và tối ưu hiệu năng cho các tenant có kích thước chênh lệch lớn.
Bốn triệu database này được phân bổ trên khoảng 3.000 server PostgreSQL tại 13 region của AWS trên toàn thế giới. Các server này thực chất là các instance của AWS RDS for PostgreSQL hoặc AWS Aurora PostgreSQL, vì vậy thuật ngữ “instance” được sử dụng thay cho “server”.
Quá trình dịch chuyển database diễn ra liên tục để cân bằng tải. Atlassian sử dụng hai phương pháp chính: đối với các database nhỏ, họ thực hiện backup và restore trên instance đích một cách nhanh chóng; đối với các database lớn hơn, họ thiết lập logical replication giữa instance nguồn và đích, cho phép sao chép dữ liệu mà không làm gián đoạn hoạt động của tenant.
Hệ thống database của họ được phân chia theo mô hình “bridge model” của AWS Well-Architected Framework: đại đa số tenant sử dụng shared infrastructure, trong khi một số ít tenant cực lớn được đặt trên dedicated infrastructure. Các tenant khổng lồ này từ lâu đã sử dụng Aurora PostgreSQL vì nó cung cấp nguồn tài nguyên vượt trội so với RDS.
Vào cuối năm 2023, Atlassian bắt đầu một dự án nghiên cứu tiềm năng: chuyển toàn bộ phần còn lại của hệ thống database Jira sang Aurora PostgreSQL. Mục tiêu của họ rất tham vọng: tối ưu chi phí, độ tin cậy và hiệu năng. Cấu hình RDS hiện tại chỉ cho phép sử dụng một instance tại một thời điểm, trong khi với Aurora, họ có thể truy cập đồng thời cả instance writer và reader. Điều này cho phép giảm kích thước instance xuống một nửa mà vẫn hiệu quả hơn. Hơn nữa, họ còn có thể tận dụng SLA tốt hơn của Aurora (99.99% so với 99.95%) và khả năng autoscaling lên tới 15 reader trong giờ cao điểm. Kết quả nghiên cứu khả quan và dự án chính thức được khởi động.
Thiết kế quy trình Migration
Với các mục tiêu đã đề ra, Atlassian cần một kế hoạch thực thi chi tiết, đồng thời phải đáp ứng các tiêu chí bổ sung:
- Giảm thiểu downtime của tenant.
- Kiểm soát chi phí bằng cách hạn chế hạ tầng phát sinh cho việc migration.
- Hoàn thành việc dịch chuyển trong một khoảng thời gian hợp lý.
Dựa trên các mục tiêu này, phương pháp tối ưu được xác định cho mỗi instance RDS PostgreSQL Multi-AZ là:
- Thêm một DB instance read replica vào instance hiện có. Replica này sẽ đồng bộ hóa toàn bộ dữ liệu sang một Aurora cluster volume mới. Đây là một tính năng tiêu chuẩn của RDS.
- Thực hiện cutover trong một khung thời gian phù hợp bằng cách promoting read replica mới thành một Aurora cluster độc lập.
Quá trình này được gọi là “conversion” một instance RDS thành một Aurora cluster. Về lý thuyết, đây là một cách tiếp cận chuẩn mực, nhưng ở quy mô của Atlassian, mọi thứ trở nên phức tạp hơn rất nhiều.
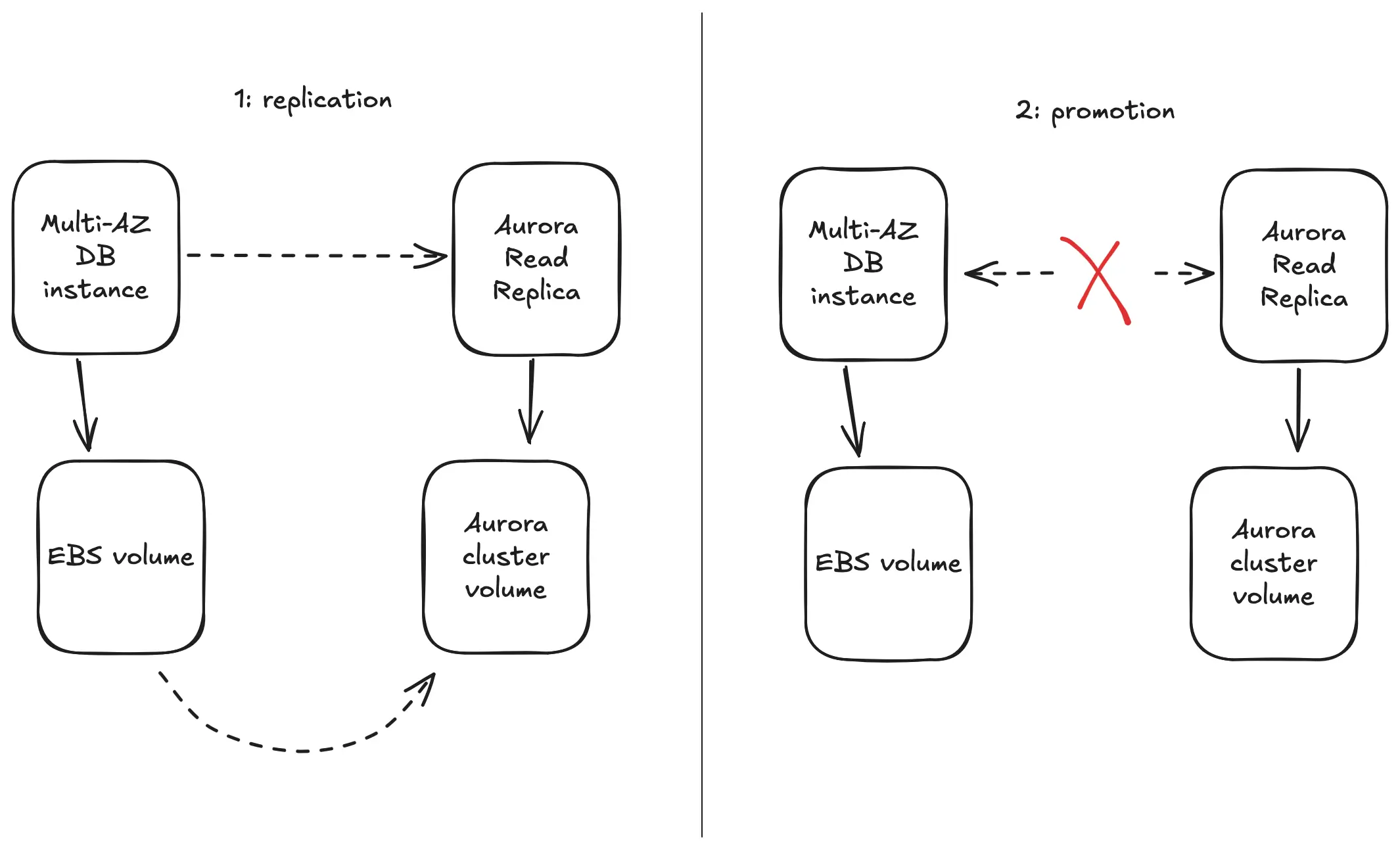
Quá trình Conversion
Phức tạp đầu tiên đến từ việc mỗi cluster của Atlassian chứa tới khoảng 4.000 database, tương ứng với 4.000 tenant Jira riêng biệt. Việc promote một replica thành Aurora cluster mới đồng nghĩa với việc phải thực hiện cutover đồng bộ cho cả 4.000 tenant, mỗi tenant lại có endpoint kết nối và thông tin xác thực riêng. Đội ngũ kỹ sư cần phải cập nhật ứng dụng Jira đang chạy trên các instance EC2 để sử dụng endpoint mới của cluster Aurora cho từng tenant, đồng thời đảm bảo an toàn tuyệt đối, không ghi nhầm vào database cũ. Để làm được điều này, quy trình cutover của họ đã khóa tất cả user SQL trên instance nguồn, hoàn thành việc promote, và sau đó chỉ mở khóa các user SQL trên cluster đích.
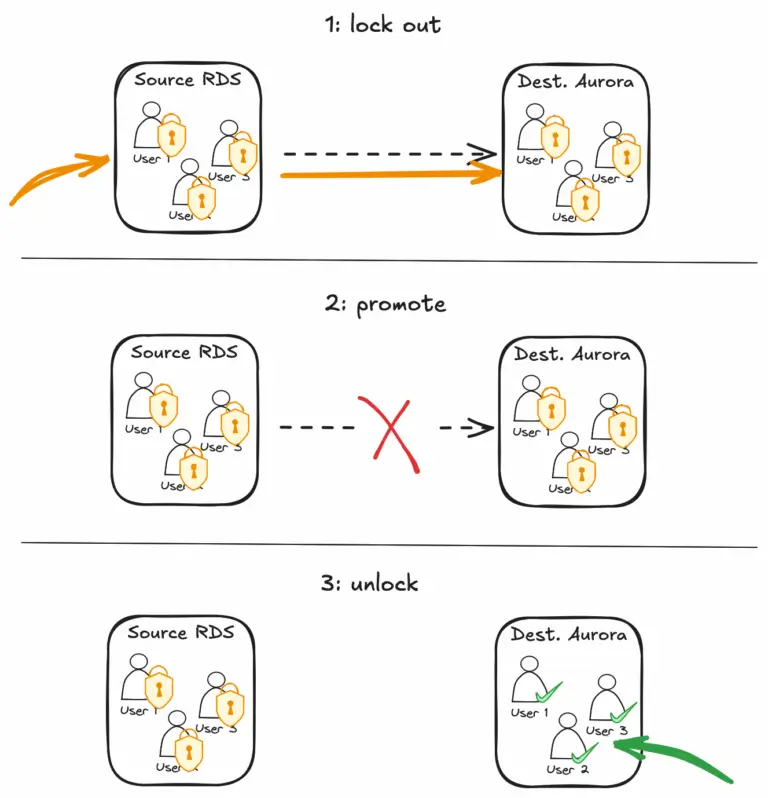
Toàn bộ quá trình này được điều phối bởi một AWS Step Function, thực hiện hàng loạt kiểm tra an toàn trước, trong và sau khi chuyển đổi. Bất kỳ sai sót nào cũng sẽ kích hoạt cơ chế quay trở lại trạng thái vận hành tiêu chuẩn. Lưu lượng truy cập của khách hàng sau khi chuyển đổi cũng được giám sát chặt chẽ trong nhiều giờ để đảm bảo mọi thứ hoạt động chính xác.
Để quá trình cutover diễn ra nhanh chóng, họ đã sử dụng feature flag: khi mọi thứ sẵn sàng, một feature flag được bật lên để ghi đè ngay lập tức endpoint database của các tenant trên các application server, thay vì chờ đợi chu kỳ làm mới định kỳ. Nhờ vậy, cùng với việc dữ liệu đã được đồng bộ hóa từ trước, thời gian cutover thực tế đã được giới hạn dưới 3 phút cho mỗi lần chuyển đổi hoàn toàn nằm trong SLA cho phép, ngay cả với những instance lớn nhất.
Giai đoạn xây dựng và thử nghiệm diễn ra suôn sẻ cho đến một ngày, team hỗ trợ của AWS liên hệ với họ. Một instance RDS thử nghiệm lớn đang trong quá trình đồng bộ hóa đã gặp sự cố: dù quá trình đồng bộ đã hoàn tất, cluster mới lại không thể khởi động. Từ phía Atlassian, AWS console vẫn hiển thị replica này ở trạng thái hoạt động tốt, nhưng control plane của AWS đã phát hiện ra rằng quá trình khởi động của instance đã bị timeout.
Nguyên nhân của việc timeout này, mà lúc đó họ chưa hề biết, là do số lượng file trên instance RDS nguồn (và do đó, trên Aurora cluster volume mới) quá lớn. Instance read replica mới đã bị timeout trong khi thực hiện một tác vụ kiểm tra trạng thái, bao gồm việc liệt kê tất cả các file đó. Càng nhiều file, quá trình này càng kéo dài và khả năng chạm đến ngưỡng timeout càng cao. Và hệ thống của họ có hàng triệu, hàng triệu file.
Vấn đề số lượng file
Trong Postgres, mỗi đối tượng cấp cao như table, index, và sequence được lưu trữ trong ít nhất một file trên đĩa. Schema của Jira có số lượng lớn các đối tượng này, dẫn đến một database Jira duy nhất cần khoảng 5.000 file trên đĩa. Với số lượng lớn database được host chung trên một instance, họ đã vô tình tạo ra một số lượng file trên Aurora cluster volume mới nhiều hơn bất kỳ khách hàng nào khác của AWS. Dù chưa sử dụng hết dung lượng lưu trữ khổng lồ của Aurora, họ đã chạm đến một giới hạn khác số lượng file.
Lời khuyên từ AWS rất rõ ràng: phải giảm đáng kể số lượng file trên các instance RDS nếu muốn thực hiện chuyển đổi sang Aurora một cách an toàn. Chỉ có hai cách để làm điều này: giảm số file trên mỗi database, hoặc giảm số database trên một instance. Vì việc giảm số file trên mỗi database là bất khả thi, con đường duy nhất còn lại là giảm số lượng tenant trên các instance cần chuyển đổi, một quy trình mà họ gọi là “draining”.
AWS cũng cho biết sau khi một instance RDS đã được chuyển đổi thành công sang Aurora cluster, họ có thể tự do re-populate nó trở lại bằng các database tenant. Điều này rất quan trọng vì nó giúp họ giảm thiểu hạ tầng phát sinh, chỉ cần cấp đủ dung lượng để chứa các tenant đang được di chuyển.
Kế hoạch mới rất đơn giản:
- Drain một instance xuống một số lượng tenant tối thiểu phù hợp.
- Convert instance đó thành một Aurora cluster.
- Refill cluster mới bằng cách sử dụng nó làm đích cho các tenant được di chuyển từ các instance tiếp theo cần “Drain”.
Cách tiếp cận này tạo ra một daisy chain gồm các instance và cluster thực hiện vòng lặp Drain–Convert–Refill, giúp duy trì chi phí hạ tầng ở mức thấp trong suốt quá trình migration.
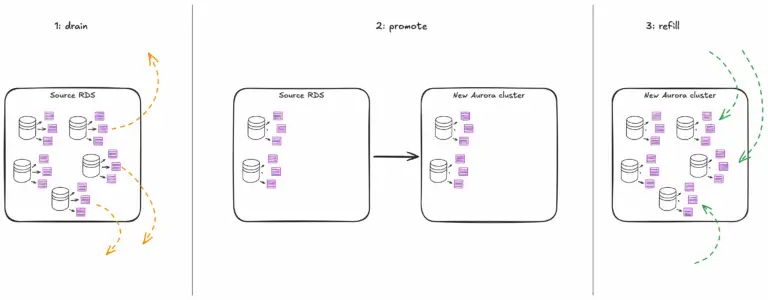
Quá trình Draining
Dựa trên lời khuyên từ AWS, Atlassian đã xây dựng một công cụ để điều phối quy trình di chuyển database hàng ngày của họ, nhưng ở một quy mô lớn hơn rất nhiều. Họ đã phân tích sự phân bổ tenant và ưu tiên di chuyển các tenant nhỏ nhất và ít sử dụng nhất trước để giảm lượng dữ liệu cần di chuyển. Vào lúc cao điểm, công cụ này đạt trung bình 38.000 lượt di chuyển mỗi ngày, với đỉnh điểm gần 90.000 là một sự gia tăng khổng lồ so với con số 1.000 thông thường. Tất cả những điều này được thực hiện trong khi vẫn đáp ứng các mục tiêu về độ tin cậy.
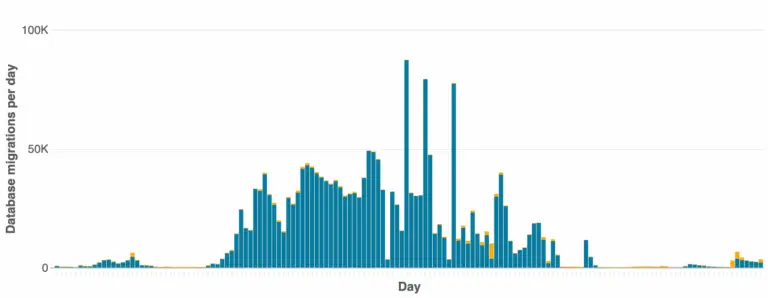
Khi một instance RDS được “Drain” đến ngưỡng số lượng file an toàn, công cụ sẽ chuyển sang các mục tiêu khác, để lại các instance đã “Drain” sẵn sàng cho quá trình Convert.
Cuộc đua về đích
Sau khi các quy trình đã được thiết lập, phần còn lại là một bài toán về các con số trong một cỗ máy được vận hành trơn tru. Họ phải kiểm soát cả concurrency nguồn (số lượng migration đi từ mỗi instance RDS) và concurrency đích (số lượng migration đến mỗi cluster Aurora) để không ảnh hưởng đến hoạt động bình thường. Cuối cùng, họ phải tìm ra sự cân bằng giữa chi phí hạ tầng bổ sung và thời gian hoàn thành dự án. Nhờ vào việc kỷ luật trong việc chuyển đổi các instance RDS đã “Drain” thành cluster Aurora càng sớm càng tốt, họ đã duy trì được tốc độ và hoàn thành dự án trước thời hạn.
Tóm tắt lại:

End Game
Dự án đã hoàn thành đúng mục tiêu, nhưng kết quả thực sự mang lại là gì?

Nhiều người có thể thắc mắc tại sao số lượng instance Aurora lại gần gấp ba lần số instance RDS trước đây. Câu trả lời nằm ở chỗ, thông qua Aurora, Atlassian đã có thể giảm kích thước class của instance xuống một nửa, từ m5.4xlarge trên RDS xuống r6.2xlarge trên Aurora, mà vẫn có được hiệu năng tốt hơn. Họ giữ nguyên dung lượng bộ nhớ nhưng giảm số lượng CPU. Việc giảm CPU này không ảnh hưởng tiêu cực, vì họ có thể sử dụng tất cả các instance trong một cluster Aurora, thay vì chỉ instance primary như cấu hình RDS cũ. Trong giờ cao điểm, các cluster sẽ scale-out; ngoài giờ cao điểm, chúng sẽ scale-in, giúp giảm đáng kể chi phí.
Cuộc dịch chuyển của Atlassian là cả ành trình và đầy thách thức về mặt kỹ thuật, nhưng đội ngũ của họ đã thành công đạt được mục tiêu tiết kiệm chi phí đầy tham vọng. Quan trọng hơn, họ còn cải thiện đáng kể độ tin cậy và hiệu suất của toàn bộ hệ thống trong quá trình đó. Đây được xem là một chiến thắng lớn cho bộ phận cơ sở dữ liệu tại Atlassian.
Cuối cùng, đội ngũ Atlassian cũng đã dành lời cảm ơn trân thành cho đội ngũ hỗ trợ của AWS đã cống hiến không mệt mỏi, hợp tác nhiệt tình để xử lý số lượng file khổng lồ, đảm bảo trải nghiệm tốt nhất cho dịch vụ Aurora.
Thông tin được chia sẻ từ blog của Atlassian.