Một tòa án liên bang Mỹ vừa buộc OpenAI phải giao nộp 20 triệu cuộc trò chuyện ChatGPT đã khử định danh trong vụ kiện bản quyền với The New York Times. Quyết định này đặt ra câu hỏi: dữ liệu chúng ta gõ vào chatbot thực sự riêng tư tới đâu?
Vụ kiện gì đang xảy ra?
Xuất phát từ đơn kiện của The New York Times và nhiều tòa soạn khác, cáo buộc OpenAI và Microsoft đã dùng trái phép kho bài báo của họ để huấn luyện các mô hình AI như ChatGPT, khiến chatbot có thể phản hồi lại các đoạn nội dung gần như nguyên văn.
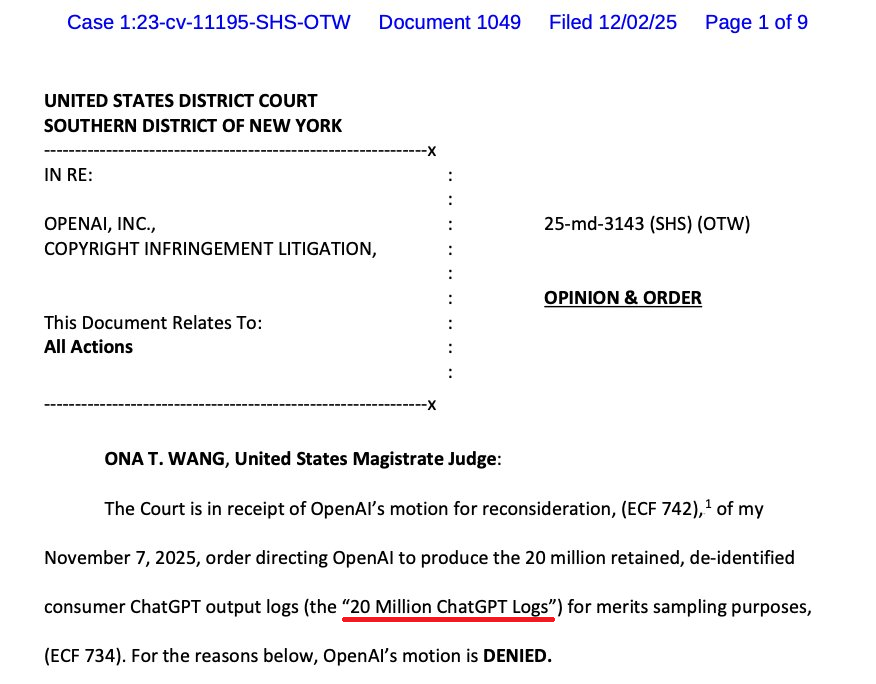
Các vụ kiện riêng lẻ được nhập lại thành một vụ kiện tập thể lớn mang tên In re: OpenAI, Inc., Copyright Infringement Litigation (1:25-md-03143, SDNY), do Thẩm phán Sidney H. Stein phụ trách, Thẩm phán Ona T. Wang làm thẩm phán hòa giải.

Để chứng minh ChatGPT thật sự tái sử dụng nội dung báo chí, phía nguyên đơn yêu cầu được tiếp cận một lượng rất lớn log cuộc trò chuyện của người dùng. Ban đầu họ đòi tới 120 triệu logs, tòa cuối cùng chọn một mẫu 20 triệu trùng với con số mà chính OpenAI từng nói là quá đủ cho mục đích nghiên cứu thống kê.
Tòa đã ra lệnh gì?
Ngày 7/11/2025, Thẩm phán Wang ra lệnh buộc OpenAI:
- Giao nộp 20 triệu log ChatGPT của người dùng trong giai đoạn khoảng từ 12/2022 đến 11/2024.
- Dữ liệu phải được khử định danh: bỏ tên, email, ID tài khoản và các thông tin nhận dạng trực tiếp khác.
- Logs chỉ được dùng để lấy mẫu phục vụ xem xét nội dung vụ kiện .
OpenAI phản đối mạnh mẽ, cho rằng:
- 99,99% các cuộc trò chuyện không liên quan gì tới cáo buộc của các tòa soạn.
- Ngay cả khi khử định danh, nội dung trò chuyện vẫn có thể chứa thông tin cực kỳ riêng tư (về sức khỏe, tài chính, cuộc sống cá nhân…).
- Việc buộc giao nộp một khối dữ liệu khổng lồ như vậy là một tiền lệ nguy hiểm làm xói mòn lòng tin của người dùng.
Ngày 2-3/12/2025, Thẩm phán Wang bác yêu cầu xin xem xét lại của OpenAI, tái khẳng định rằng:
- Việc giao nộp 20 triệu logs là phù hợp và tương xứng với nhu cầu chứng minh trong vụ kiện.
- Đã có nhiều tầng bảo vệ: dữ liệu được khử định danh, đặt dưới lệnh bảo vệ bí mật, chỉ một số người (luật sư, chuyên gia, tòa) được truy cập, và mọi tài liệu nhạy cảm phải được đóng dấu hoặc “Attorneys’ Eyes Only”.
OpenAI vẫn có thể kháng nghị lên cấp cao hơn, nhưng hiện tại lệnh giao nộp vẫn có hiệu lực và công ty bị yêu cầu bàn giao dữ liệu trong thời hạn ngắn.
Điều này có nghĩa là cuộc trò chuyện của bạn sắp bị công khai?
Không hẳn. Quan trọng cần hiểu:
-
Dữ liệu không bị dump lên mạng: Các log này là chứng cứ trong một vụ kiện dân sự, nên nằm trong hệ thống lưu trữ bảo mật của tòa và các bên liên quan. Nếu ai đó làm lộ hoặc phát tán ra ngoài có thể bị chế tài rất nặng.
-
Đã được khử định danh, nhưng không có nghĩa là 100% vô danh: Tòa yêu cầu OpenAI xóa thông tin định danh trực tiếp. Tuy nhiên, nội dung hội thoại đôi khi vẫn chứa chi tiết đủ để nhận diện một người (ví dụ: tên công ty nhỏ, bệnh hiếm, địa chỉ cụ thể…). Đây chính là điều mà OpenAI viện dẫn khi nói rằng người dùng có thể bị tổn hại nếu dữ liệu bị lạm dụng.
-
Chỉ là một mẫu lớn, không phải tất cả mọi cuộc trò chuyện: 20 triệu logs là con số khổng lồ, nhưng vẫn chỉ là một phần nhỏ so với tổng số tương tác mà ChatGPT xử lý. Thời gian, phạm vi, cách chọn mẫu cụ thể không được công khai chi tiết, nhưng các tài liệu tòa cho thấy nó tập trung vào giai đoạn 2022–2024, thời điểm liên quan trực tiếp tới các mô hình bị kiện.
Vụ việc cho thấy gì về quyền riêng tư khi dùng chatbot?
Cho dù bạn có dùng ChatGPT hay các AI khác, vụ kiện này nhắc lại một số thực tế không dễ chịu:
-
Nội dung bạn gõ vào có thể được lưu, dùng để đào tạo hoặc trở thành chứng cứ
- OpenAI công khai cho biết: với dịch vụ dành cho cá nhân như ChatGPT, nội dung trò chuyện có thể được dùng để cải thiện mô hình, trừ khi bạn tắt tuỳ chọn “Improve the model for everyone” hoặc bật chế độ Temporary Chat.
- Chính sách cũng nêu rõ: dữ liệu có thể được giữ lại lâu hơn 30 ngày nếu bị yêu cầu vì lý do pháp lý hoặc an ninh như trong trường hợp lệnh bảo toàn chứng cứ và lệnh giao nộp 20 triệu logs lần này.
-
Tòa án có thể buộc các công ty AI cung cấp dữ liệu người dùng
- Không chỉ trong vụ NYT, nhiều chuyên gia lưu ý rằng các lệnh bảo quản và giao nộp dữ liệu (legal hold, discovery) đang trở thành chuẩn mực mới trong tranh chấp liên quan đến AI.
-
Không có đặc quyền nghề nghiệp cho chatbot
- Khi bạn kể chuyện sức khỏe, chuyện gia đình, tranh chấp pháp lý… với một chatbot, không có cơ chế bảo mật tương đương quan hệ bác sĩ-bệnh nhân hoặc luật sư-thân chủ. Các cuộc trò chuyện này, về nguyên tắc, có thể bị yêu cầu cung cấp trước tòa nếu liên quan đến vụ việc nào đó.
Người dùng nên làm gì?
Vụ việc không có nghĩa là mọi câu chữ bạn từng gõ vào ChatGPT sẽ bị công khai, nhưng nó là lời nhắc rất rõ rằng hãy cẩn thận với những thứ bạn đã đưa vào trò chuyện với AI. Một số gợi ý thực tế:
-
Không đưa thông tin siêu nhạy cảm
- Tránh nhập số CMND/hộ chiếu, số thẻ ngân hàng, mật khẩu, mã OTP, hồ sơ sức khỏe chi tiết, bí mật kinh doanh cốt lõi hoặc bất cứ thứ gì bạn sẽ không gửi qua email không mã hóa.
-
Dùng các chế độ riêng tư sẵn có
- Trong ChatGPT, hãy vào Settings → Data Controls và tắt “Improve the model for everyone” nếu bạn không muốn nội dung được dùng để huấn luyện.
- Khi trao đổi nội dung nhạy cảm, cân nhắc dùng Temporary Chat để lịch sử không lưu lâu và không dùng cho huấn luyện (dù vẫn có thể bị giữ tối đa 30 ngày vì lý do an toàn).
-
Tách dữ liệu thực khỏi nội dung ví dụ
- Nếu cần nhờ AI xem xét tài liệu hay tình huống, hãy ẩn hoặc thay thế tên thật, số liệu cụ thể bằng thông tin giả (A, B, Công ty X…), trừ khi bạn đang sử dụng bản doanh nghiệp được bảo đảm hợp đồng riêng.
-
Nhớ rằng nhiều nhà cung cấp AI khác cũng lưu logs
- Không chỉ OpenAI, các công ty như Anthropic, Google, v.v. đều sử dụng log để huấn luyện và cải thiện mô hình, trừ khi bạn chủ động opt-out hoặc dùng gói doanh nghiệp.