FinOps trong Kubernetes: Không chỉ là Tiết kiệm Tiền, mà là Cách Anh Em Mình “Làm Giàu” Cho Công Ty
Chào anh em DevOps đang “đau đầu” với mấy cái hóa đơn cloud nhé. Bài viết này chắc anh em nào nhiều năm kinh nghiệm đọc sẽ thấm hơn và cũng chém hơi dài dài anh em nào đọc thêm kinh nghiệm thực tế thì đọc ông nào lười thì kệ. Anh em mình cứ thế thôi hẹ hẹ hẹ =)))
Anh em mình làm với Cloud, với Kubernetes chắc không lạ gì cái cảnh “tiền cứ vơi dần vơi dần” mà nhiều khi chẳng hiểu nó đi đâu đúng không? Mới đầu thì hào hứng lắm, nào là scale vô tư, tài nguyên bạt ngàn. Nhưng rồi cứ đến cuối tháng, nhìn cái bill mà muốn “rụng rời tay chân”. Cái này không chỉ mấy ông lớn mới bị đâu, ngay cả mấy startup nhỏ nhỏ cũng “khóc thầm” vì tiền cloud đấy.
Đây chính là lúc FinOps “ra tay” đấy anh em ạ. Nghe cái tên FinOps có vẻ hơi “tài chính” một chút, nhưng thật ra nó là cây cầu nối cực kỳ quan trọng giữa đội ngũ kỹ thuật (chính là anh em mình đây) và mấy bác bên tài chính. Mục tiêu không phải là cứ nhắm mắt nhắm mũi cắt giảm chi phí đâu, mà là làm sao để tiêu ít tiền nhất nhưng vẫn mang lại giá trị kinh doanh cao nhất cho công ty. Hay nói nôm na là, làm sao để tiền mình bỏ ra nó “đẻ” ra nhiều giá trị nhất, chứ không phải “bay hơi” vô ích.
Hôm nay, mình sẽ cùng anh em đi sâu vào FinOps trong môi trường Kubernetes, từ những khái niệm cơ bản nhất đến mấy cái chiêu trò và công cụ “xịn sò” mà anh em có thể áp dụng ngay vào công việc của mình nhé.
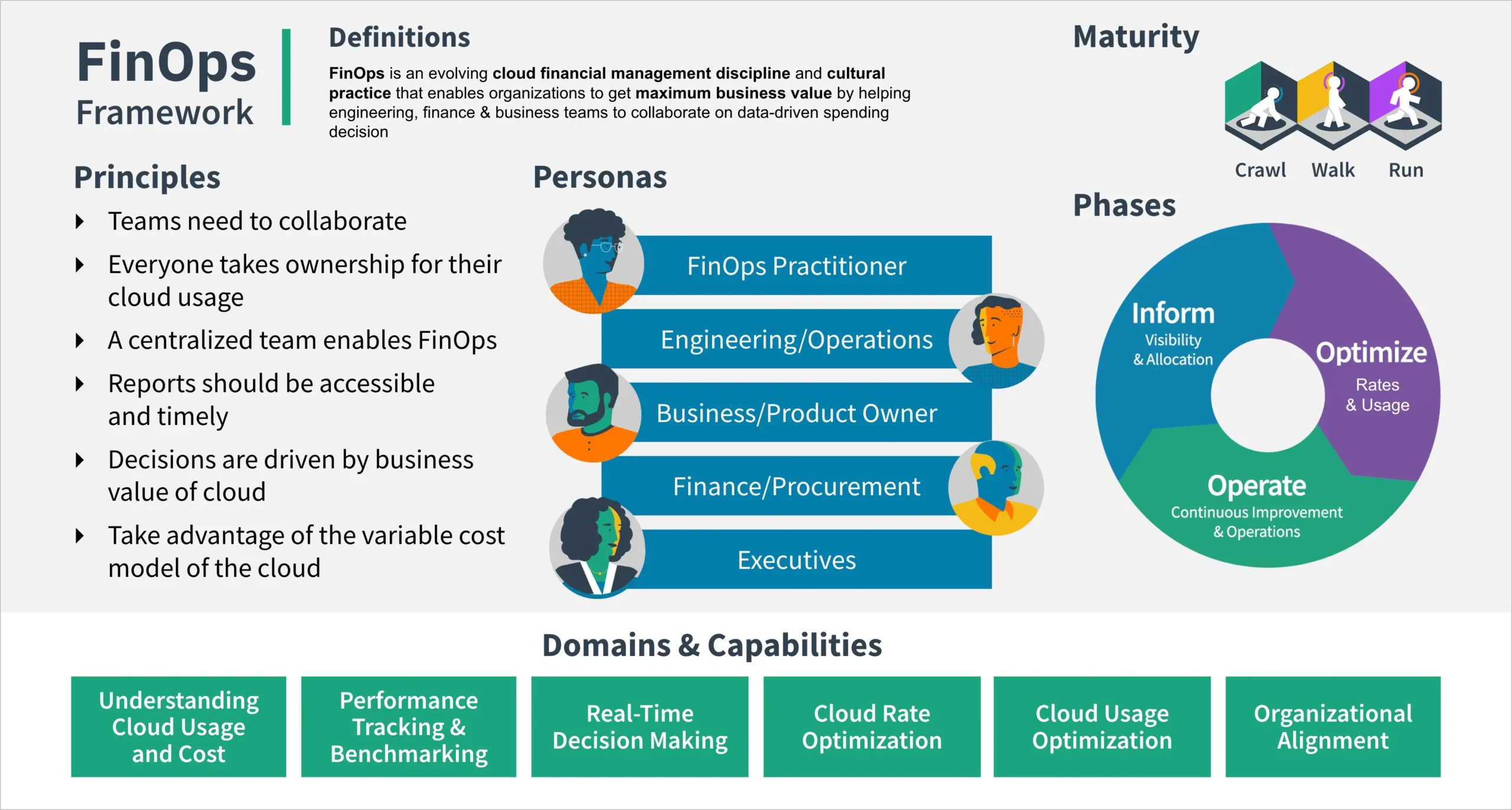
1. FinOps là cái gì mà nghe lạ thế? Và tại sao anh em mình phải “để ý” đến nó?
FinOps không phải là một công nghệ mới toanh, cũng chẳng phải là một phần mềm nào cả. Nó là một cách làm việc, một văn hóa chung giúp các công ty quản lý tiền bạc trên đám mây hiệu quả hơn. Nó đẩy mạnh việc bắt tay giữa mấy ông Kỹ thuật, mấy ông Vận hành (Ops) và mấy bác Tài chính để cùng nhau đưa ra quyết định dựa trên số liệu về chi phí.
Ba cái “chân kiềng” của FinOps là:
- Hiểu Rõ (Inform): Phải làm sao cho tất cả mọi người, từ anh em kỹ thuật đến bác quản lý, đều nhìn rõ tiền đang đi đâu, con số cụ thể là bao nhiêu. Mình phải biết tiền mình đang tiêu vào cái gì chứ!
- Tối Ưu (Optimize): Cứ phải liên tục tìm cách cải thiện, làm cho tài nguyên mình dùng hiệu quả hơn, giảm bớt chi phí không cần thiết. Đây chính là lúc kỹ năng DevOps của anh em mình được “lên ngôi” đấy.
- Vận Hành (Operate): Thiết lập các quy trình, dùng công cụ và xây dựng một cái “văn hóa” để việc tối ưu chi phí này nó diễn ra liên tục, thành một thói quen tốt chứ không phải làm theo kiểu “chộp giật”.
Vậy tại sao anh em DevOps chúng ta phải “quan tâm” đến FinOps?
Đơn giản thôi anh em. Anh em mình là người trực tiếp xây dựng, triển khai và vận hành mấy cái ứng dụng trên Kubernetes. Anh em là người hiểu rõ nhất mấy cái Pod, Deployment, Service nó đang “ngốn” tài nguyên như thế nào. Nếu không có sự tham gia của anh em, việc tối ưu chi phí sẽ chỉ là mấy con số trên giấy tờ thôi, không thể phản ánh đúng thực tế được.
Hơn nữa, khi anh em chủ động “nhúng tay” vào FinOps, anh em sẽ:
- Hiểu rõ hơn về giá trị mình mang lại: Thấy được công việc của mình ảnh hưởng trực tiếp đến “túi tiền” của công ty như thế nào.
- Có tiếng nói hơn: Khi mình hiểu về chi phí, mình có thể đề xuất các giải pháp kỹ thuật “ngon – bổ – rẻ” mà vẫn đảm bảo hệ thống chạy tốt.
- Nâng cao tay nghề: Mình sẽ học được thêm về cách quản lý tài nguyên, tối ưu hệ thống sao cho “khéo”.
- Xây dựng tinh thần “có trách nhiệm”: Ai cũng sẽ thấy mình có phần trách nhiệm với chi phí hạ tầng, không còn tình trạng “cứ xài thoải mái đi, có người trả tiền”.
2. Mấy cái “khó nhằn” khi quản lý tiền bạc trong Kubernetes
Kubernetes thì “ngon” đấy, nhưng đi kèm với nó là mấy cái rắc rối không nhỏ khi quản lý chi phí:
- Nó cứ “nhảy múa” liên tục (Dynamic Nature): Mấy cái Pods cứ liên tục được tạo ra, xóa đi, phình to rồi lại co lại. Việc theo dõi chính xác thằng nào đang dùng bao nhiêu tài nguyên cực kỳ khó luôn.
- Nhiều “hộ” dùng chung (Multi-tenancy): Một cụm Kubernetes có khi cả chục ứng dụng, cả chục đội nhóm cùng dùng chung. Giờ phân bổ chi phí công bằng cho từng team, từng dự án kiểu gì đây?
- Tài nguyên “lằng nhằng”: Nào là CPU, Memory, Disk, Network, GPU… Mỗi loại lại có cách tính tiền khác nhau, rối rắm lắm anh em ạ.
- Khó mà “nhìn rõ” (Lack of Visibility): Mấy cái công cụ monitoring mặc định của Kubernetes (như
kubectl top) thì chỉ cho cái nhìn tổng quan, không đủ chi tiết để mình “mổ xẻ” chi phí. - Chi phí “tàng hình” (Hidden Costs): Mấy cái chi phí mạng giữa các vùng, chi phí “xuất dữ liệu” (egress data transfer), chi phí của mấy cái dịch vụ đi kèm như Load Balancer, Managed Database… dễ bị anh em mình bỏ qua lắm. Tích tiểu thành đại là “toang” đấy!
3. Mấy cái chiêu và công cụ “thực chiến” để anh em mình tối ưu chi phí Kubernetes
Đây mới là phần anh em mình mong chờ nhất đây. Mình sẽ chỉ cho anh em mấy chiến lược từ dễ đến khó, kèm theo mấy cái công cụ cụ thể để anh em mình về áp dụng luôn nhé.
3.1. Phải “Nhìn Thấy” Mọi Thứ Trước Đã (Thiết lập Observability về Chi phí)
Trước khi muốn tiết kiệm, anh em phải biết mình đang “đổ” tiền vào đâu cái đã. Đây là bước đầu tiên và quan trọng nhất trong FinOps.
-
Dùng mấy công cụ “chuyên trị”:
-
Kubecost (Mình highly recommend thằng này): Đây là “ông trùm” trong mảng FinOps cho Kubernetes luôn. Nó cho anh em mình cái nhìn cực kỳ chi tiết về chi phí theo Pod, theo Deployment, theo Namespace, theo từng team, từng dịch vụ, và thậm chí cả chi phí của mấy cái tài nguyên đám mây (node, Persistent Volume, network) mà cụm Kubernetes đang dùng.
- Mấy điểm “ăn tiền” của nó: Phân bổ chi phí rành mạch, tìm ra tài nguyên lãng phí, cảnh báo khi chi phí “vọt” lên, thậm chí còn ước tính được chi phí cho mấy cái ứng dụng mới nếu mình triển khai. Nó còn tích hợp với mấy nhà cung cấp cloud để khớp nối chi phí thực tế nữa.
Để cài đặt Kubecost, anh em cứ dùng Helm là nhanh nhất:
helm repo add kubecost https://kubecost.github.io/cost-analyzer/ helm install kubecost kubecost/cost-analyzer --namespace kubecost --create-namespaceCài xong thì anh em truy cập vào UI của Kubecost là tha hồ mà “soi” báo cáo chi phí nhé.
-
OpenCost: Đây là một dự án mã nguồn mở, được phát triển dựa trên tiêu chuẩn OpenCost của Cloud Native Computing Foundation (CNCF). Nó cung cấp các tính năng gần giống Kubecost nhưng hoàn toàn miễn phí và được cộng đồng ủng hộ nhiệt tình.
Cài đặt OpenCost cũng đơn giản lắm, dùng Helm là xong:
helm repo add opencost https://opencost.github.io/helm-charts helm install opencost opencost/opencost -n opencost --create-namespaceSau khi cài đặt, anh em cứ truy cập vào UI của OpenCost để xem dữ liệu.
-
-
Tích hợp với hệ thống Monitoring có sẵn (Prometheus/Grafana): Anh em mình cũng có thể dùng Prometheus để thu thập các số liệu về việc sử dụng tài nguyên, rồi xây mấy cái dashboard “xịn sò” trên Grafana để theo dõi hiệu suất và ước tính chi phí. Tuy nhiên, việc khớp nối mấy cái số liệu này với chi phí thực tế từ nhà cung cấp cloud sẽ phức tạp hơn nhiều và đòi hỏi anh em phải “tự chế” đấy.
3.2. Cấu hình “đúng chuẩn” cho Pods (Resource Requests & Limits)
Đây là một trong những cách “hái ra tiền” dễ nhất để tiết kiệm chi phí trong Kubernetes. Nếu anh em không cấu hình resources.requests và resources.limits cho Pods một cách hợp lý, hệ thống sẽ chạy rất kém hiệu quả và tốn tiền lắm.
requests(yêu cầu): Là lượng CPU và Memory tối thiểu mà một Pod cần được cấp phát để “được sống”. Cái này quan trọng cực kỳ vì nó ảnh hưởng trực tiếp đến việc Kubernetes Scheduler “nhét” Pod đó vào Node nào. Nếu anh em đặtrequestsquá cao, cái Pod đó có khi chiếm dụng tài nguyên không cần thiết, gây lãng phí và làm mấy Pod khác “chết đói” vì không có chỗ.limits(giới hạn): Là lượng CPU và Memory tối đa mà một Pod được phép sử dụng. Nếu Pod “ăn” quáCPU limit, nó sẽ bị bóp hiệu năng (throttle). Còn nếu vượt quáMemory limit, nó sẽ bị “giết chết” (OOMKilled) ngay lập tức.
Mấy cái “chiêu” để tối ưu:
- Đo đạc thật kỹ: Dùng mấy công cụ như Prometheus, Grafana, cAdvisor hoặc thậm chí là Vertical Pod Autoscaler (VPA) để thu thập số liệu sử dụng tài nguyên thực tế của ứng dụng ở cả mức tải bình thường và cao điểm. Cứ phải có số liệu thì mới “phán” được anh em ạ.
- Đặt Requests thấp, Limits hợp lý:
- Requests: Nên đặt gần với mức tài nguyên mà ứng dụng dùng trung bình. Như vậy Pods sẽ được “nhét” vào Node hiệu quả hơn, không bị lãng phí tài nguyên trên các Node.
- Limits: Đặt cao hơn một chút so với mức sử dụng cao điểm để ứng dụng có “khoảng trống” để xử lý khi có nhiều request đột biến mà không bị “chết” hay bị bóp hiệu năng quá đáng.
- Hiểu về Quality of Service (QoS): Kubernetes có 3 mức QoS, nó ảnh hưởng đến việc Pod của anh em có dễ bị “đuổi” khỏi Node hay không khi Node thiếu tài nguyên:
- Guaranteed: Khi
requestsbằnglimitscho cả CPU và Memory. Mấy Pods ở mức này là “con cưng”, ít khi bị “đuổi” nhất. - Burstable: Khi
requestsnhỏ hơnlimitscho ít nhất một tài nguyên. Mấy Pods này có thể bị “đuổi” khi Node hết tài nguyên. - BestEffort: Không khai báo
requestsvàlimitsgì cả. Mấy Pods này là “con ghẻ”, bị kill đầu tiên khi Node gặp áp lực tài nguyên. Anh em mình nên tránh dùng BestEffort trong môi trường production nhé.
- Guaranteed: Khi
Ví dụ cấu hình resources trong Deployment YAML (anh em xem rồi áp dụng nhé):
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-web-app
spec:
replicas: 3
selector:
matchLabels:
app: my-web-app
template:
metadata:
labels:
app: my-web-app
spec:
containers:
- name: my-container
image: my-image:latest
resources:
requests:
cpu: "200m" # Yêu cầu 20% của 1 core CPU (0.2 CPU core)
memory: "256Mi" # Yêu cầu 256 Megabytes RAM
limits:
cpu: "500m" # Giới hạn 50% của 1 core CPU (0.5 CPU core)
memory: "512Mi" # Giới hạn 512 Megabytes RAM
ports:
- containerPort: 80- Vertical Pod Autoscaler (VPA): Nếu anh em không muốn đau đầu với việc “chỉnh tay” mấy con số
requestsvàlimits, thì VPA là một “bảo bối” đấy. VPA sẽ tự động điều chỉnhresources.requestsvàresources.limitscho các Pods dựa trên lịch sử sử dụng tài nguyên của chúng.- Ưu điểm: Tự động hoàn toàn, giảm lãng phí tài nguyên do mình cấu hình “quá tay”.
- Nhược điểm: Hiện tại (tính đến thời điểm mình viết bài này), VPA yêu cầu Pods phải được khởi động lại mới áp dụng được các thay đổi về tài nguyên. Cái này có thể gây gián đoạn nhẹ nếu anh em không có chiến lược roll out phù hợp. Nhưng mà cộng đồng đang phát triển để VPA có thể update mà không cần restart đấy.
3.3. Tối ưu số lượng và kích thước Nodes (Node Sizing & Autoscaling)
Đây là một trong những khoản chi lớn nhất trong Kubernetes. Anh em mình phải “cân nhắc” kỹ lưỡng.
-
Chọn Node “vừa miếng” (Right-sizing Nodes): Lựa chọn kích thước Node (số core CPU, RAM) phải phù hợp với các Pods đang chạy trên đó. Tránh chọn Node quá lớn nếu đa số Pods của anh em chỉ cần ít tài nguyên, vì như thế là đang “vứt tiền qua cửa sổ” cho mấy cái tài nguyên chưa dùng đấy (unused capacity).
-
Node Autoscaler (Cluster Autoscaler): Cái này thì chắc chắn phải có rồi. Cluster Autoscaler sẽ tự động thêm hoặc bớt Nodes trong cụm Kubernetes dựa trên nhu cầu tài nguyên của Pods.
- Khi có Pods không được xếp lịch vì không đủ tài nguyên, Cluster Autoscaler sẽ “gọi” thêm Node mới.
- Khi có Node nào đó “rảnh rỗi” (ít Pods chạy, tài nguyên sử dụng thấp), nó sẽ “đá” cái Node đó đi để tiết kiệm tiền.
- Cách thức hoạt động của Cluster Autoscaler (anh em hình dung nhé): Mình cứ tưởng tượng mình có một bể bơi tài nguyên, mà mấy cái Node là mấy cái phao. Khi Pods cần thêm chỗ, Cluster Autoscaler sẽ “thả” thêm phao vào bể. Khi Pods bớt đi và có phao trống, nó sẽ “nhặt” bớt phao ra khỏi bể để giảm chi phí.
Ví dụ về cách Cluster Autoscaler làm việc:
- Anh em deploy một ứng dụng (Deployment) với 10 bản sao (replicas), mỗi bản sao yêu cầu 1GB RAM.
- Cụm Kubernetes hiện tại chỉ còn đủ chỗ cho 5 bản sao.
- 5 bản sao còn lại sẽ ở trạng thái
Pending(chờ được xếp lịch). - Cluster Autoscaler nhận ra có Pods đang “chờ” và không có Node nào đủ tài nguyên.
- Nó sẽ “xin” nhà cung cấp cloud (AWS, GCP, Azure) cấp thêm 1 hoặc 2 Node mới (tùy vào cấu hình của anh em).
- Khi Node mới sẵn sàng, Kubernetes Scheduler sẽ “nhét” các Pods
Pendingvào các Node mới này. - Về sau, nếu các Pods này bị xóa và Node trở nên rảnh rỗi (sử dụng ít tài nguyên, đủ điều kiện để bị thu hồi), Cluster Autoscaler sẽ tự động giảm số lượng Node xuống.
-
Dùng Spot Instances/Preemptible VMs: Mấy loại máy ảo này có giá rẻ hơn rất nhiều (có khi tới 70-90%) so với các máy ảo thông thường, nhưng có một điều cần lưu ý là chúng có thể bị nhà cung cấp cloud “thu hồi” bất cứ lúc nào.
- Khi nào thì nên dùng: Phù hợp cho mấy cái ứng dụng có thể chịu lỗi tốt (fault-tolerant), không lưu trạng thái (stateless), có thể chạy ngắt quãng như các tác vụ tính toán lớn (batch jobs), hàng đợi (queues), hoặc môi trường phát triển/test.
- Cách dùng hiệu quả trong Kubernetes: Kết hợp với Node Autoscaler và Pod Disruption Budgets để đảm bảo hệ thống vẫn ổn định ngay cả khi Node bị thu hồi. Anh em có thể dùng Karpenter (một công cụ open-source của AWS, nhưng có thể dùng được trên các cloud khác) để quản lý Spot Instances trong Kubernetes một cách thông minh hơn, nó sẽ tìm kiếm Node phù hợp và rẻ nhất cho Pods của anh em.
3.4. Quản lý Persistent Volumes (PVs) hiệu quả
Dữ liệu là “vàng”, nhưng lưu trữ dữ liệu cũng tốn tiền không kém.
- Chọn loại lưu trữ phù hợp: Không phải lúc nào cũng cần SSD hiệu năng cao (IOPS cao) đâu anh em. Với mấy cái ứng dụng không yêu cầu tốc độ đọc/ghi quá khủng khiếp, anh em có thể dùng loại lưu trữ rẻ hơn như HDD hoặc General Purpose SSD với IOPS thấp hơn.
- Dọn dẹp PVs không dùng đến: Cái này dễ bị bỏ qua lắm. Khi một ứng dụng bị xóa, Persistent Volume Claim (PVC) có thể bị xóa nhưng Persistent Volume (PV) underlying có thể vẫn còn đó, và anh em mình vẫn phải trả tiền cho nó. Hãy có quy trình định kỳ rà soát và xóa bớt những PVs không còn được dùng nữa.
- Sử dụng Snapshot hiệu quả: Snapshot thì tiện lợi đấy, nhưng cũng tốn tiền nếu anh em tạo quá nhiều hoặc không có quy trình xóa các snapshot cũ. Chỉ nên giữ lại những snapshot cần thiết thôi nhé.
3.5. Áp dụng các Chiến lược Tối ưu Ứng dụng
Ngoài việc tối ưu hạ tầng, việc tối ưu bản thân ứng dụng cũng cực kỳ quan trọng.
- Tối ưu Code và Image:
- Giảm kích thước Docker Image: Dùng các base image nhẹ hơn (như Alpine), loại bỏ các thư viện, công cụ không cần thiết trong image. Image nhỏ hơn thì deploy nhanh hơn, ít tốn băng thông, và có thể giúp Pod khởi động nhanh hơn.
- Tối ưu hóa Code: Viết code hiệu quả hơn, giảm thiểu việc sử dụng CPU/Memory không cần thiết.
-
Sử dụng Horizontal Pod Autoscaler (HPA): HPA tự động tăng hoặc giảm số lượng Pods (replicas) của ứng dụng dựa trên các metrics như CPU usage, Memory usage, hoặc các metrics tùy chỉnh khác (ví dụ: số lượng request trên giây).
- Lợi ích: Đảm bảo ứng dụng luôn có đủ tài nguyên để xử lý tải, đồng thời không lãng phí tài nguyên khi tải thấp. Thay vì cứ chạy 10 bản sao 24/7, có khi chỉ cần 2 bản sao lúc bình thường và 10 bản sao lúc cao điểm thôi.
-
Ví dụ HPA dựa trên CPU:
apiVersion: autoscaling/v2 kind: HorizontalPodAutoscaler metadata: name: my-web-app-hpa spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: my-web-app minReplicas: 2 # Số lượng Pod tối thiểu maxReplicas: 10 # Số lượng Pod tối đa metrics: - type: Resource resource: name: cpu target: type: Utilization averageUtilization: 70 # Tự động scale khi CPU utilization đạt 70%
- Triển khai Sleep/Wakeup: Đối với các môi trường Dev/Test hoặc các ứng dụng không hoạt động 24/7, anh em có thể tự động “tắt” (scale về 0 replicas) các Deployment hoặc cụm Kubernetes khi không có ai dùng, và “đánh thức” chúng dậy khi cần. Cái này tiết kiệm tiền cực kỳ luôn.
3.6. Dọn dẹp tài nguyên “bỏ đi” (Garbage Collection)
Kubernetes và đám mây đôi khi tạo ra những tài nguyên “rác” mà anh em mình không để ý.
- Xóa bỏ Load Balancers/Ingresses không dùng: Khi xóa một Service
type: LoadBalancerhoặc một Ingress, đôi khi Load Balancer tương ứng trên cloud không bị xóa tự động. Anh em cần kiểm tra và dọn dẹp định kỳ. - Xóa các Image cũ/không dùng: Các registry (như Docker Hub, ECR, GCR) có thể chứa rất nhiều image cũ, đã lỗi thời. Dọn dẹp chúng để tiết kiệm chi phí lưu trữ.
- Kiểm tra các Snapshots/Backups: Như đã nói ở phần PVs, các bản sao lưu và snapshot cũng tốn tiền.
4. Xây dựng văn hóa FinOps trong team
Cuối cùng, nhưng không kém phần quan trọng, là việc xây dựng một văn hóa FinOps trong công ty.
- Giáo dục và Đào tạo: Cho anh em kỹ thuật hiểu rõ về chi phí đám mây, cách các hành động của họ ảnh hưởng đến hóa đơn.
- Thiết lập trách nhiệm rõ ràng: Ai chịu trách nhiệm cho chi phí nào? Phân bổ chi phí cho từng team, từng dự án.
- Minh bạch hóa dữ liệu: Chia sẻ báo cáo chi phí thường xuyên, không giấu diếm. Khi mọi người cùng nhìn thấy con số, họ sẽ có động lực để tối ưu.
- Thúc đẩy hợp tác: FinOps không phải là việc của riêng một nhóm nào. Nó là sự hợp tác giữa Engineering, Ops và Finance.
- Đặt mục tiêu và khen thưởng: Đặt ra các mục tiêu tiết kiệm chi phí và có phần thưởng xứng đáng cho các nhóm đạt được mục tiêu đó.
Lời kết
FinOps trong Kubernetes không phải là một công việc “một sớm một chiều” đâu anh em. Nó là một hành trình liên tục, đòi hỏi sự kiên trì, theo dõi sát sao và liên tục học hỏi. Nhưng mình tin rằng, nếu anh em mình áp dụng đúng cách, không chỉ giúp công ty tiết kiệm được kha khá tiền mà còn giúp hệ thống của chúng ta chạy hiệu quả hơn, ổn định hơn.
Hãy bắt đầu từ những bước nhỏ nhất, như việc cài đặt Kubecost hay OpenCost để có cái nhìn rõ ràng về chi phí. Sau đó, từ từ áp dụng các chiến lược tối ưu tài nguyên, và quan trọng nhất là xây dựng một văn hóa FinOps trong team của mình.
Chúc anh em thành công và “làm giàu” cho công ty nhé =))). Nếu có bất kỳ thắc mắc hay kinh nghiệm nào muốn chia sẻ, đừng ngần ngại để lại bình luận nhé. Anh em mình cùng học hỏi.