Mới đây mình có setup PostgreSQL High-Availability cho dự án mới thấy cách này cũng khá được, nhanh mà cơ bản bằng ansible, bản chất thì vẫn là dùng Patroni. Trước giờ vẫn hay dùng pgpool nay đổi gió thử. Thấy bài của ông anh khác viết trước đây về Patroni này đỉnh cao phết đấy mọi người có thể tham khảo Triển khai PostgreSQL high availability với Patroni trên Ubuntu (Cực kỳ chi tiết).
Điều kiện tiên quyết
Trước khi bắt đầu, hãy đảm bảo bạn đã có:
- Tối thiểu 3 máy ảo Linux (đã thử nghiệm trên Ubuntu 22.04)
- Có thể SSH giữa các node
- Python cài trên máy điều khiển Ansible
- Ansible phiên bản 2.10 trở lên
- Git
- (Tuỳ chọn) NFS mount để lưu trữ WAL archiving (thực tế mount dữ liệu là hiển nhiên rồi)
Step 1: Clone repository GitHub
git clone https://github.com/akylson/postgresql_cluster.git
cd postgresql_clusterRepo này bao gồm:
- Các Ansible role theo mô-đun
- Template dựng sẵn cho Patroni, PostgreSQL, Etcd, HAProxy
- Ví dụ inventory
- WAL archiving (qua NFS + cron + custom
archive_command)
Step 2: Chỉnh sửa Inventory
Mở file inventory và thay IP thật của bạn:
[etcd_cluster] # khuyến nghị: 3, hoặc 5-7 node (etcd nên là số lẻ, ai chưa biết research cho hiểu rõ nhé)
192.168.132.11
192.168.132.12
192.168.132.13
# nếu dcs_exists: false và dcs_type: "consul"
[consul_instances] # khuyến nghị: 3, hoặc 5–7 node
192.168.132.11 consul_node_role=server consul_bootstrap_expect=true consul_datacenter=dc1
192.168.132.12 consul_node_role=server consul_bootstrap_expect=true consul_datacenter=dc1
192.168.132.13 consul_node_role=server consul_bootstrap_expect=true consul_datacenter=dc1
# nếu with_haproxy_load_balancing: true
[balancers]
192.168.132.11
192.168.132.12
192.168.132.13
# PostgreSQL nodes
[master]
192.168.132.11 hostname=pgnode01 postgresql_exists='false'
[replica]
192.168.132.12 hostname=pgnode02 postgresql_exists='false'
192.168.132.13 hostname=pgnode03 postgresql_exists='false'
[postgres_cluster:children]
master
replica
# nếu pgbackrest_install: true và "repo_host" được cấu hình
[pgbackrest] # tuỳ chọn (Dedicated Repository Host)
# Cấu hình kết nối
[all:vars]
ansible_connection='ssh'
ansible_ssh_port='22'
ansible_user='root'
ansible_ssh_pass='secretpassword' # cần cài gói "sshpass" để dùng ansible_ssh_pass
[pgbackrest:vars]
ansible_user='postgres'
ansible_ssh_pass='secretpassword'Bạn có thể gộp nhiều vai trò trên cùng node (ví dụ: 3 node đều chạy Etcd, Patroni, PostgreSQL).
Step 3: Chạy Playbook Ansible
Để bắt đầu cài đặt toàn bộ cluster:
ansible-playbook deploy_pgcluster.yml --ask-become-passPlaybook sẽ cài đặt:
- PostgreSQL
- Patroni (bật auto-failover)
- Etcd (làm DCS)
- HAProxy (định tuyến read/write)
- WAL archiving (nếu cấu hình)
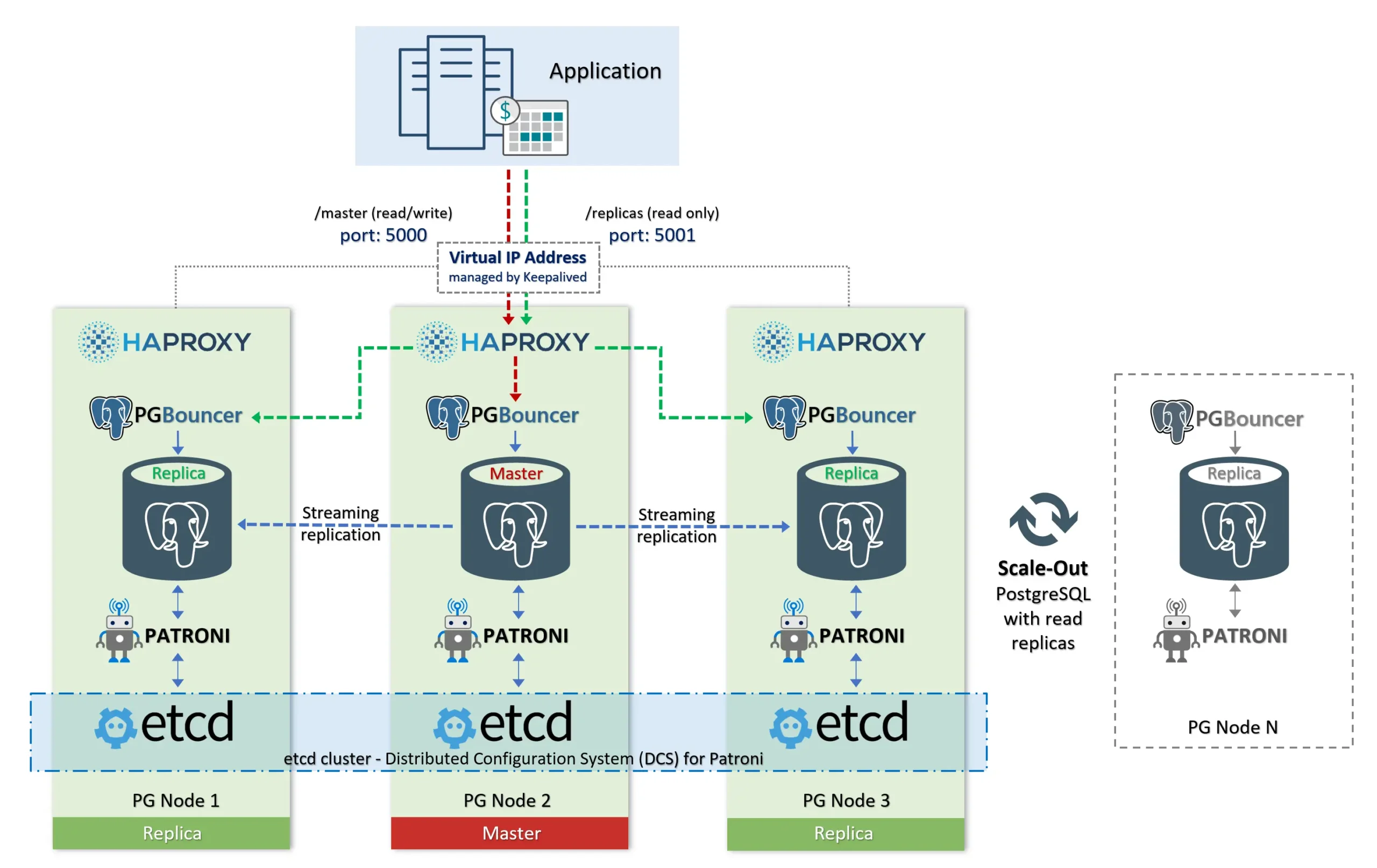
Step 4: Kiểm tra Cluster
SSH vào bất kỳ node nào và chạy:
patronictl listKết quả hiển thị node leader, trạng thái replica, độ trễ (lag), v.v.
Kết quả mẫu patronictl list
# chạy trên bất kỳ node nào
patronictl list+ Cluster: pgcluster (7098234759012345678) ----------------------------+
| Member | Host | Role | State | TL | Lag in MB | Pending restart |
+----------+-----------------+---------+---------+----+-----------+-----------------+
| pgnode01 | 192.168.132.11 | Leader | running | 5 | | No |
| pgnode02 | 192.168.132.12 | Replica | running | 5 | 0 | No |
| pgnode03 | 192.168.132.13 | Replica | running | 5 | 0 | No |
+----------+-----------------+---------+---------+----+-----------+-----------------+
# DCS: etcd | PostgreSQL: 16.x | Patroni: 3.xKết quả mẫu kiểm tra chi tiết 1 member
patronictl member pgnode01Member: pgnode01
Cluster: pgcluster
Host: 192.168.132.11
Role: Leader
State: running
Timeline: 5
Replication: streaming (2 standbys)
Tags: nofailover: false, noloadbalance: false, clonefrom: falseKiểm tra kết nối qua HAProxy (read/write vs read-only)
Giả sử HAProxy lắng nghe:
- cổng 5000: route về leader (RW)
- cổng 5001: route về replicas (RO)
# RW qua HAProxy (mong đợi pg_is_in_recovery() = false)
psql "host=192.168.132.11 port=5000 user=postgres dbname=postgres" -c \
"select inet_server_addr() as backend_ip, pg_is_in_recovery() as is_ro;" backend_ip | is_ro
----------------+-------
192.168.132.11 | f
(1 row)# RO qua HAProxy (mong đợi pg_is_in_recovery() = true)
psql "host=192.168.132.11 port=5001 user=postgres dbname=postgres" -c \
"select inet_server_addr() as backend_ip, pg_is_in_recovery() as is_ro;" backend_ip | is_ro
----------------+-------
192.168.132.12 | t
(1 row)
Kiểm tra DCS etcd (tùy chọn, nếu bạn muốn chèn thêm)
# ví dụ
etcdctl --endpoints="http://192.168.132.11:2379,http://192.168.132.12:2379,http://192.168.132.13:2379" endpoint status -w table+--------------------+------------------+---------+---------+-----------+-----------+------------+
| ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER| RAFT INDEX |
+--------------------+------------------+---------+---------+-----------+-----------+------------+
| 192.168.132.11:2379| 9c6b... | 3.5.x | 25 MB | true | false | 12345678 |
| 192.168.132.12:2379| a7d1... | 3.5.x | 25 MB | false | false | 12345678 |
| 192.168.132.13:2379| b88e... | 3.5.x | 25 MB | false | false | 12345678 |
+--------------------+------------------+---------+---------+-----------+-----------+------------+Nâng cao: WAL Archiving với NFS (khuyến nghị)
Thiết lập này đảm bảo cluster PostgreSQL có thể phục hồi thông qua WAL backup.
1. Mount NFS trên tất cả node
Giả sử NFS server là 192.168.132.10:/mnt/storages/k8s-mount-storage:
sudo mkdir -p /data
sudo mount -t nfs 192.168.132.10:/mnt/storages/k8s-mount-storage /dataĐể mount cố định:
echo "192.168.132.10:/mnt/storages/k8s-mount-storage /data nfs defaults 0 0" | sudo tee -a /etc/fstab2. Cấu hình archive_command trong Ansible vars
Trong file group_vars/all.yml:
archive_mode: "on"
archive_command: "cp %p /data/wal_backup/%f"3. Tạo script xoay vòng WAL
Tạo file /usr/local/bin/rotate_wal.sh:
#!/usr/bin/env bash
set -euo pipefail
# Nhớ: tạo sẵn thư mục /data/wal_backup và chown cho postgres:postgres
BACKUP_DIR="/data/wal_backup"
MAX_WALS=2000
mkdir -p "$BACKUP_DIR"
cd "$BACKUP_DIR"
# chỉ tính file bình thường, sort theo mtime mới→cũ rồi bỏ qua MAX_WALS file đầu
# lưu ý: --no-run-if-empty để tránh lỗi khi không có file
find . -maxdepth 1 -type f -printf "%T@ %p\n" \
| sort -nr \
| awk "NR>${MAX_WALS} {print \$2}" \
| xargs --no-run-if-empty rm -fCấp quyền thực thi:
chmod +x /usr/local/bin/rotate_wal.sh4. Thêm Cron Job
Chỉnh crontab -e cho user postgres:
0 * * * * /usr/local/bin/rotate_wal.sh >> /var/log/wal_rotate.log 2>&1Cron job chạy mỗi giờ, chỉ giữ lại 2000 WAL file gần nhất.
Tóm tắt
Sau khi triển khai, chúng ta có:
- PostgreSQL cluster chịu lỗi (fault-tolerant)
- Tự động failover & health checks
- HAProxy load balancing cho truy cập đọc/ghi
- Tuỳ chọn backup WAL trên NFS
- Toàn bộ cài đặt tự động với Ansible